

Web scraping of the most frequent english words
If you’re interested in learning new languages, it’s important to be able to speak with a good accent, to understand speeches or discussions, read books but also to have enough vocabulary.
My English is not as fluent as it used to be, but i’ve decided to work on it. So the question : is how many words in a foreign language you need to know ? Well, the CEFR English levels can provide the beginning of an answer :
| Levels | Description | Nb words | % |
|---|---|---|---|
| A1 | Beginner | 0-2000 | >80% |
| A2 | Elementary | 2000-2750 | |
| B1 | Intermediate | 2750–3250 | 95% |
| B2 | Upper-Intermediate | 3250–3750 | |
| C1 | Advanced | 3750–4500 | |
| C2 | Proficiency | 4500–5000 | 98% |
CEFR English levels are used by all modern English language books and English language schools. It is recommended to use CEFR levels in job resumes (curriculum vitae, CV, Europass CV) and other English level references.
An article from BBC.com intitled “How many words do you need to speak a language?” can bring other explanations on the table :
“[…] it is incredibly difficult for a language learner to ever know as many words as a native speaker.
Typically native speakers know 15,000 to 20,000 word families - or lemmas - in their first language.
[…] So does someone who can hold a decent conversation in a second language know 15,000 to 20,000 words? Is this a realistic goal for our listener to aim for? Unlikely.
Prof Webb found that people who have been studying languages in a traditional setting - say French in Britain or English in Japan - often struggle to learn more than 2,000 to 3,000 words, even after years of study.
In fact, a study in Taiwan showed that after nine years of learning a foreign language half of the students failed to learn the most frequently-used 1,000 words.
And that is the key, the frequency with which the words you learn appear in day-to-day use in the language you’re learning.
You don’t need to know all of the words in a language […]
So which words should we learn? Prof Webb says the most effective way to be able to speak a language quickly is to pick the 800 to 1,000 lemmas which appear most frequently in a language, and learn those.
If you learn only 800 of the most frequently-used lemmas in English, you’ll be able to understand 75% of the language as it is spoken in normal life.”
By searching the web for the most frequently used words, you can quickly arrive on the OxfordLearnersDictionaries.com webpage :
The Oxford 5000 is an expanded core word list for advanced learners of English. … the frequency of the words in the Oxford English Corpus, a database of over 2 billion words from different subject areas and contexts which covers British, American and world English.
… and it could be very interesting to scrape all those words, translate them, and put all of it in an anki deck to memorize all this good stuff !
Download the list of all words
First things first, let’s grab the word list of Oxford 3000 and 5000. This part of the script provides different user agent in order to not get rapidly flagged as a bot, and a function to retrieve a specific web page by its URL with the help of the requests module :
import pandas as pd
import requests
from bs4 import BeautifulSoup
from requests.exceptions import HTTPError
from random import randint
import time
user_agents = [
{'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"},
{'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36"},
{'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0"},
{'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36"},
{'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"},
{'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36"},
{'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"},
{'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Safari/605.1.15"},
{'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"},
{'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0"},
{'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36"},
{'User-Agent': "Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36"},
{'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:15.0) Gecko/20100101 Firefox/15.0.1"},
{'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.246"}
]
def retrieve_webpage(req_url):
"""Get a webpage with the requests module & return the response"""
try:
req_response = requests.get(req_url, headers=user_agents[randint(0, len(user_agents))])
req_response.raise_for_status()
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err} for URL {req_url}')
return None
except Exception as err:
print(f'Other error occurred: {err} for URL {req_url}')
return None
else:
# print('Request success!')
return req_response
time.sleep(2.4) # in sec
url_wordlist = "https://www.oxfordlearnersdictionaries.com/wordlists/oxford3000-5000"
req_response = retrieve_webpage(url_wordlist)
if not req_response :
print("fail")
elif str(req_response) == '<Response [200]>':
print("success")
else:
print("something wrong")
Then, we’ll use Beautifulsoup to parse the html page and retrieve the data we need : the word itself, its phonetic pronunciation, its CEFR level, the url of the web page describing each word, the type (verb, noun…) and the american sound (an .mp3 file).
In order to achieve this goal, it’s required to dive deep in the CSS code of the page, to analyze the nested class and their parameters. For instance, in the dev tools of your browser, by clicking on a specific word on the left, you’ll see hightlighted the line of the code where the corresponding text can be found.
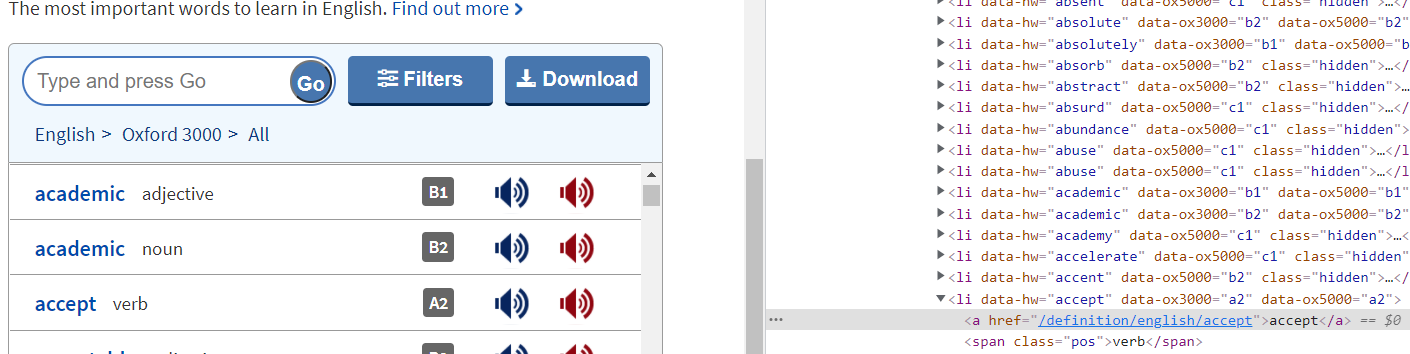
s = BeautifulSoup(req_response.content, 'html.parser')
all_elts = s.find_all("li")[34:-44]
words, levels, def_urls, types, sound_urls = [], [], [], [], []
for i in all_elts:
i = str(i)
if "data-hw" in i:
words.append(i.split('data-hw="')[1].split('"')[0])
else:
words.append("No word")
if "data-ox5000" in i:
levels.append(i.split('data-ox5000="')[1].split('"')[0])
else:
levels.append("No level")
if "href" in i:
def_urls.append(i.split('href="')[1].split('"')[0])
else:
def_urls.append("No def_url")
if 'class="pos' in i:
types.append(i.split('class="pos">')[1].split('<')[0])
else:
types.append("No types")
if "data-src-mp3" in i:
sound_urls.append(i.split('pron-us" data-src-mp3="')[1].split('"')[0])
else:
sound_urls.append("No sound url")
df = pd.DataFrame(list(zip(words, levels, def_urls, types, sound_urls)), columns =['words', 'levels', 'def_urls', 'types', 'sound_urls'])
df.to_csv('words_list', index=False)
df.head(3)
| words | levels | def_urls | types | sound_urls | |
|---|---|---|---|---|---|
| 0 | a | a1 | /definition/english/a_1 | indefinite article | /media/english/us_pron/a/a__/a__us/a__us_2_rr.mp3 |
| 1 | abandon | b2 | /definition/english/abandon_1 | verb | /media/english/us_pron/a/aba/aband/abandon__us... |
| 2 | ability | a2 | /definition/english/ability_1 | noun | /media/english/us_pron/a/abi/abili/ability__us... |
There isn’t any null data in our pandas dataframe, so it seems that we have retrieved all the infos we were looking for…
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5948 entries, 0 to 5947
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 words 5948 non-null object
1 levels 5948 non-null object
2 def_urls 5948 non-null object
3 types 5948 non-null object
4 sound_urls 5948 non-null object
dtypes: object(5)
memory usage: 232.5+ KB
Anyway some levels are filled with the default values, but not so many lines are concerned :
df[df['levels'] == 'No level']
| words | levels | def_urls | types | sound_urls | |
|---|---|---|---|---|---|
| 47 | accounting | No level | /definition/english/accounting | noun | /media/english/us_pron/a/acc/accou/accounting_... |
| 233 | angrily | No level | /definition/english/angrily | adverb | /media/english/us_pron/a/ang/angri/angrily__us... |
| 889 | cleaning | No level | /definition/english/cleaning | noun | /media/english/us_pron/c/cle/clean/cleaning__u... |
| 2058 | feeding | No level | /definition/english/feeding | noun | /media/english/us_pron/f/fee/feedi/feeding__us... |
| 3176 | major | No level | /definition/english/major_2 | noun | /media/english/us_pron/m/maj/major/major__us_2... |
Let’s insert the corresponding value :
df.loc[df[df['levels'] == 'No level'].index, 'levels'] = 'a1'
df[df['sound_urls'] == 'No sound url']
| words | levels | def_urls | types | sound_urls | |
|---|---|---|---|---|---|
| 3559 | nursing | b2 | /definition/english/nursing | noun | No sound url |
Furthermore, there isn’t any duplicated line in our dataframe:
df[df.duplicated()].shape[0]
0
Data cleaning & transformation
We concatenate the relative path with the base url to get the full link. We can also format the level, change a little bit the word type and so on…
BASE_URL = "https://www.oxfordlearnersdictionaries.com"
df['def_urls'] = df['def_urls'].apply(lambda x: BASE_URL + x)
df['levels'] = df['levels'].apply(lambda x: x.upper())
df['types'] = df['types'].apply(lambda x: "(" + x + ")")
df['sound_urls'] = df['sound_urls'].apply(lambda x: BASE_URL + x)
df['sound_files'] = df['sound_urls'].apply(lambda x: x.split("/")[-1])
df.head()
| words | levels | def_urls | types | sound_urls | sound_files | |
|---|---|---|---|---|---|---|
| 0 | a | A1 | https://www.oxfordlearnersdictionaries.com/def... | (indefinite article) | https://www.oxfordlearnersdictionaries.com/med... | a__us_2_rr.mp3 |
| 1 | abandon | B2 | https://www.oxfordlearnersdictionaries.com/def... | (verb) | https://www.oxfordlearnersdictionaries.com/med... | abandon__us_2.mp3 |
| 2 | ability | A2 | https://www.oxfordlearnersdictionaries.com/def... | (noun) | https://www.oxfordlearnersdictionaries.com/med... | ability__us_4.mp3 |
| 3 | able | A2 | https://www.oxfordlearnersdictionaries.com/def... | (adjective) | https://www.oxfordlearnersdictionaries.com/med... | able__us_2.mp3 |
| 4 | abolish | C1 | https://www.oxfordlearnersdictionaries.com/def... | (verb) | https://www.oxfordlearnersdictionaries.com/med... | abolish__us_1.mp3 |
Retrieve the sound files
This can be done with a python script or using few shell commands like the ones below:
!mkdir sounds
with open("./sounds" + "/" + "url_list.txt", "w") as outfile:
outfile.write("\n".join(set(df['sound_urls'])))
!cd sounds, wget -i url_list.txt
Final step : scraping of all the web pages
Now, we’ll loop over the wordlist, and for each element, we use the previous function to retrieve the webpage of the word definition. The beautifulsoup part is more tedious, because it’s not so easy to find the relevant infos. Here, several tries and errors are mandatory. Imho, using a jupyternotebook is more convenient.
def get_data(resp):
"""Parse HTTP response of a single webpage with BS4 and return relevant data"""
soup = BeautifulSoup(resp.content, 'html.parser')
try:
phonetic = soup.find_all("div", class_="phons_n_am")[0].find_all("span", class_="phon")[0].contents[0]
except:
pass
try:
senses = soup.find_all("li", class_="sense")
except:
pass
try:
definitions = [se.find_all(class_="def")[0].contents[0] for se in senses]
definitions = [f"{i+1}. {def_.replace(';', ',')}" for i, def_ in enumerate(definitions)]
except:
pass
try:
examples = [] # a list of (list of examples for one definition)
for se in senses:
all_examples = se.find_all("ul", class_="examples")[0].find_all(htag="li")
try:
all_examples = [e.contents[0].text for e in all_examples]
except:
try:
all_examples = [ex.find_all(class_="x")[0].text for ex in all_ex]
except:
pass
examples.append("".join(["<dd>- " + e.replace(';', ',') + "<br>" for e in all_examples ]))
except:
pass
return phonetic, definitions, examples
df_test = df.iloc[:20]
df_test
| words | levels | def_urls | types | sound_urls | sound_files | |
|---|---|---|---|---|---|---|
| 0 | a | A1 | https://www.oxfordlearnersdictionaries.com/def... | (indefinite article) | https://www.oxfordlearnersdictionaries.com/med... | a__us_2_rr.mp3 |
| 1 | abandon | B2 | https://www.oxfordlearnersdictionaries.com/def... | (verb) | https://www.oxfordlearnersdictionaries.com/med... | abandon__us_2.mp3 |
| 2 | ability | A2 | https://www.oxfordlearnersdictionaries.com/def... | (noun) | https://www.oxfordlearnersdictionaries.com/med... | ability__us_4.mp3 |
| 3 | able | A2 | https://www.oxfordlearnersdictionaries.com/def... | (adjective) | https://www.oxfordlearnersdictionaries.com/med... | able__us_2.mp3 |
| 4 | abolish | C1 | https://www.oxfordlearnersdictionaries.com/def... | (verb) | https://www.oxfordlearnersdictionaries.com/med... | abolish__us_1.mp3 |
| 5 | abortion | C1 | https://www.oxfordlearnersdictionaries.com/def... | (noun) | https://www.oxfordlearnersdictionaries.com/med... | abortion__us_1.mp3 |
| 6 | about | A1 | https://www.oxfordlearnersdictionaries.com/def... | (adverb) | https://www.oxfordlearnersdictionaries.com/med... | about__us_1.mp3 |
| 7 | about | A1 | https://www.oxfordlearnersdictionaries.com/def... | (preposition) | https://www.oxfordlearnersdictionaries.com/med... | about__us_1.mp3 |
| 8 | above | A1 | https://www.oxfordlearnersdictionaries.com/def... | (adverb) | https://www.oxfordlearnersdictionaries.com/med... | above__us_2.mp3 |
| 9 | above | A1 | https://www.oxfordlearnersdictionaries.com/def... | (preposition) | https://www.oxfordlearnersdictionaries.com/med... | above__us_2.mp3 |
| 10 | abroad | A2 | https://www.oxfordlearnersdictionaries.com/def... | (adverb) | https://www.oxfordlearnersdictionaries.com/med... | abroad__us_4.mp3 |
| 11 | absence | C1 | https://www.oxfordlearnersdictionaries.com/def... | (noun) | https://www.oxfordlearnersdictionaries.com/med... | absence__us_1.mp3 |
| 12 | absent | C1 | https://www.oxfordlearnersdictionaries.com/def... | (adjective) | https://www.oxfordlearnersdictionaries.com/med... | absent__us_1.mp3 |
| 13 | absolute | B2 | https://www.oxfordlearnersdictionaries.com/def... | (adjective) | https://www.oxfordlearnersdictionaries.com/med... | absolute__us_1_rr.mp3 |
| 14 | absolutely | B1 | https://www.oxfordlearnersdictionaries.com/def... | (adverb) | https://www.oxfordlearnersdictionaries.com/med... | absolutely__us_1_rr.mp3 |
| 15 | absorb | B2 | https://www.oxfordlearnersdictionaries.com/def... | (verb) | https://www.oxfordlearnersdictionaries.com/med... | absorb__us_2_rr.mp3 |
| 16 | abstract | B2 | https://www.oxfordlearnersdictionaries.com/def... | (adjective) | https://www.oxfordlearnersdictionaries.com/med... | abstract__us_2_rr.mp3 |
| 17 | absurd | C1 | https://www.oxfordlearnersdictionaries.com/def... | (adjective) | https://www.oxfordlearnersdictionaries.com/med... | absurd__us_1_rr.mp3 |
| 18 | abundance | C1 | https://www.oxfordlearnersdictionaries.com/def... | (noun) | https://www.oxfordlearnersdictionaries.com/med... | abundance__us_1.mp3 |
| 19 | abuse | C1 | https://www.oxfordlearnersdictionaries.com/def... | (noun) | https://www.oxfordlearnersdictionaries.com/med... | abuse__us_3.mp3 |
this final part will fill in the scraped data into our first dataframe.
for url in df_test["def_urls"].values: #list(df_test["def_urls"]):
time.sleep(randint(2, 9)) # in sec
req_response = retrieve_webpage(url.strip())
if not req_response :
continue
elif str(req_response) == '<Response [200]>':
# success"
phonetic, definitions, examples = get_data(req_response)
df_test.loc[df_test[df_test['def_urls'] == url].index, 'phonetic'] = phonetic
for i, def_ in enumerate(definitions):
#df_test.loc[df_test['def_urls'] == url][f'definition_{i+1}'] = def_
df_test.loc[df_test[df_test['def_urls'] == url].index, f'definition_{i+1}'] = def_
for i, ex in enumerate(examples):
df_test.loc[df_test[df_test['def_urls'] == url].index, f'examples_{i+1}'] = ex
else:
print("something wrong !! for URL {url}")
df_test.head()
| words | levels | def_urls | types | sound_urls | sound_files | phonetic | definition_1 | definition_2 | definition_3 | ... | examples_3 | examples_4 | examples_5 | examples_6 | examples_7 | examples_8 | examples_9 | examples_10 | definition_11 | definition_12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | a | A1 | https://www.oxfordlearnersdictionaries.com/def... | (indefinite article) | https://www.oxfordlearnersdictionaries.com/med... | a__us_2_rr.mp3 | /ə/ | 1. used before countable or singular nouns ref... | 2. used to show that somebody/something is a m... | 3. any, every | ... | <dd>- A lion is a dangerous animal.<br> | <dd>- a good knowledge of French<br><dd>- a sa... | <dd>- a knife and fork<br> | <dd>- A thousand people were there.<br> | <dd>- They cost 50p a kilo.<br><dd>- I can typ... | <dd>- She's a little Greta Thunberg.<br> | <dd>- There's a Mrs Green to see you.<br> | <dd>- She died on a Tuesday.<br> | NaN | NaN |
| 1 | abandon | B2 | https://www.oxfordlearnersdictionaries.com/def... | (verb) | https://www.oxfordlearnersdictionaries.com/med... | abandon__us_2.mp3 | /əˈbændən/ | 1. to leave somebody, especially somebody you ... | 2. to leave a thing or place, especially becau... | 3. to stop doing something, especially before ... | ... | <dd>- They abandoned the match because of rain... | <dd>- The baby had been abandoned by its mothe... | <dd>- He abandoned himself to despair.<br> | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | ability | A2 | https://www.oxfordlearnersdictionaries.com/def... | (noun) | https://www.oxfordlearnersdictionaries.com/med... | ability__us_4.mp3 | /əˈbɪləti/ | 1. the fact that somebody/something is able to... | 2. a level of skill or intelligence | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | able | A2 | https://www.oxfordlearnersdictionaries.com/def... | (adjective) | https://www.oxfordlearnersdictionaries.com/med... | able__us_2.mp3 | /ˈeɪbl/ | 1. to have the skill, intelligence, opportunit... | 2. intelligent, good at something | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | abolish | C1 | https://www.oxfordlearnersdictionaries.com/def... | (verb) | https://www.oxfordlearnersdictionaries.com/med... | abolish__us_1.mp3 | /əˈbɑːlɪʃ/ | 1. to officially end a law, a system or an ins... | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 29 columns
Conclusion
The final python script and the csv files are available in my Github repository dedicated to scraping stuff.
This little project is a good example of scraping static webpage. Don’t forget that Beautifulsoup is not suited when it comes to deal will pages including embedded javascript. In an other post, i’ll share tips and code built upon the selenium package able to translate automatically those words. And finally, i’ll show you how to use a csv file to create an anki deck that you can freely use to memorize all this vocabulary.
