

What is federated learning?
Table of content:
- Introduction
- How FL works? (Technical overview)
- Different types of FL
- Open source frameworks
- Applications / Examples
- Challenges and considerations
- Final thoughts
- References
Introduction
Existing data is not fully exploited primarily because it sits in silos and privacy concerns restrict its access.
Even if data anonymisation could bypass some limitations, removing metadata or PII is often not enough to preserve privacy. Another reason why data sharing is not systematic is that collecting, curating, and maintaining high-quality datasets takes considerable time, effort, and expense. Consequently such data sets may have significant business value, making it less likely that they will be freely shared. Furthermore, with creativity and “thinking out of the box” one can invent new use cases from your data…
Centralising or releasing data, however, poses not only regulatory, ethical and legal challenges, related to privacy and data protection, but also technical ones. Controlling access and safely transferring it is a non-trivial, and sometimes impossible task.
“[…] Collaborative learning without centralising data or the promise of federated efforts…”
Federated learning (FL) is a learning paradigm seeking to address the problems of data governance and privacy by training algorithms collaboratively without exchanging the data itself.

Originally developed for different domains, such as mobile and edge device use cases, it recently gained attention for other applications.
How FL works? (Technical overview)
ML algorithms are hungry for data. Furthermore, the real-world performance of your ML model depends not only on the amount of data but also the relevance of the training data.
The ML process occurs locally at each participating institution and only model characteristics (e.g., parameters, gradients) are transferred. Let’s see how it works step by step:
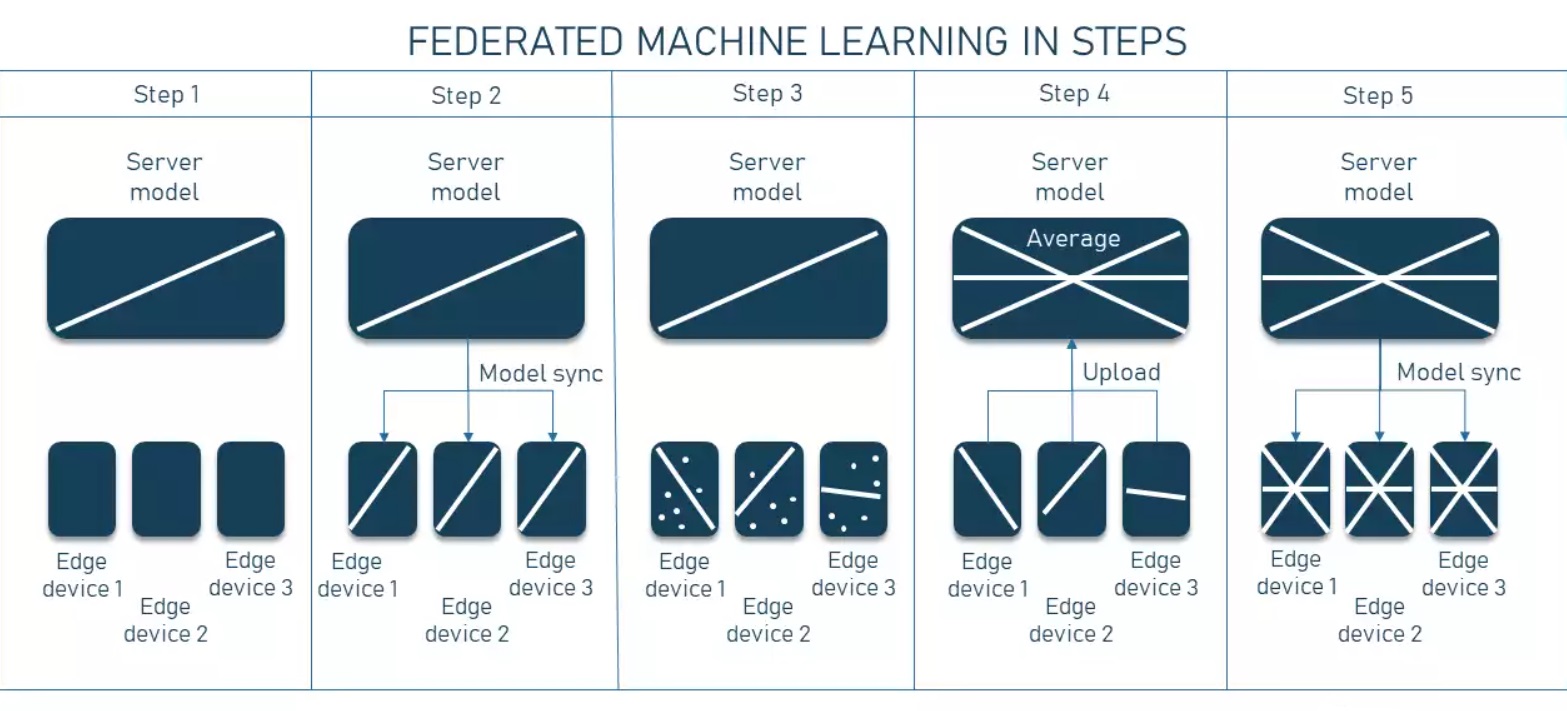
- Choose a model (either pre-trained or not) on the central server.
- Distribute this initial model to the clients (devices / local servers).
- Each client keeps “confidentially” training it on-site using its own local data.
- Then the locally trained models are sent back to the central server via encrypted communication channels. The updates from all clients are averaged / aggregated into a single shared improved model.
- Finally, this model is sent back to all devices & servers.
The cool part is that the training process in federated learning is iterative. This means the server and clients can send the updated parameters back and forth multiple times, enabling a continuous share of knowledge among participants.
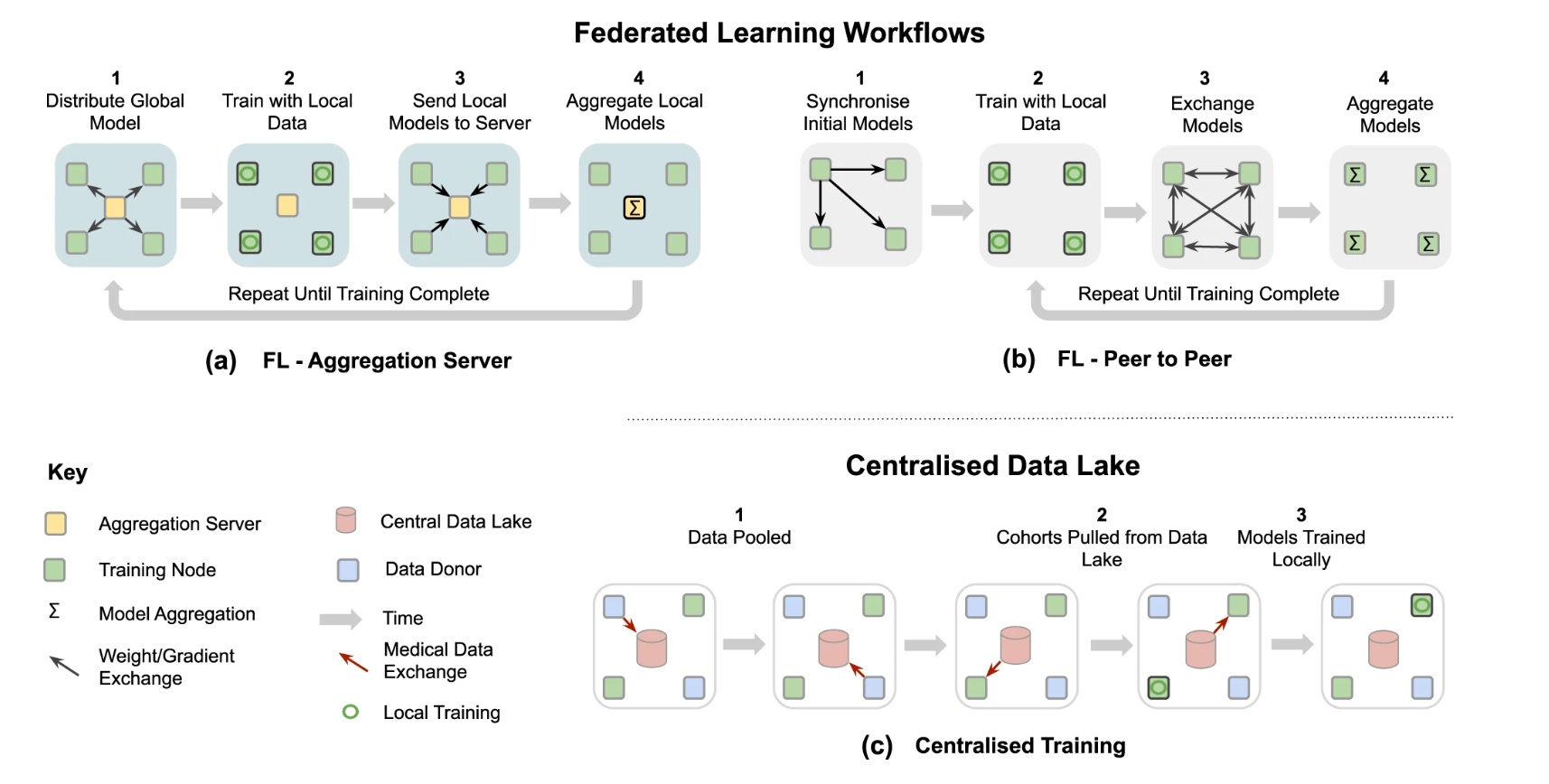
Here is an other illustration on how it works:
For IOT or edge computing, the process breakdown is quite similar & can be summarized by the picture below:
Your phone personalizes the model locally, based on your usage ( A ). Many users’ updates are aggregated ( B ) to form a consensus change ( C ) to the shared model, after which the procedure is repeated.
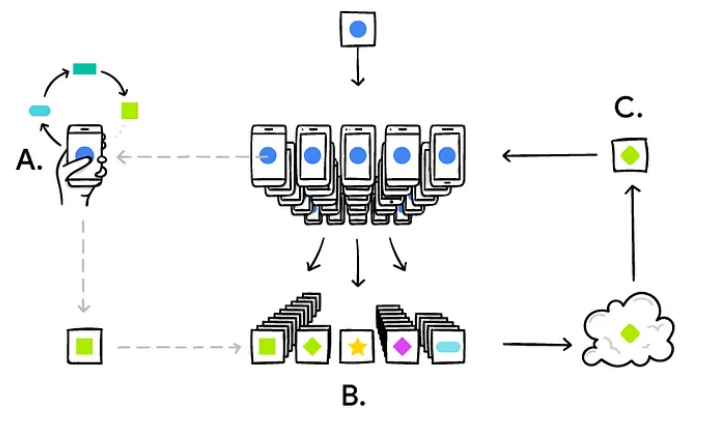
An important note is that the training data still remains on the user’s device; only the training result is encrypted and sent to the cloud. This collaborative way of training and developing machine learning models is powerful and has real-world applications.
“[…] only the model updates and parameters are shared, not the training data itself….”
Recent research has shown that models trained by FL can achieve performance levels comparable to ones trained on centrally hosted data sets and superior to models that only see isolated single-institutional data.
How the model aggregation is actually done?
The global loss function is obtained via a weighted combination of K local losses computed from private data Xk, which is residing at the individual involved parties and never shared among them:
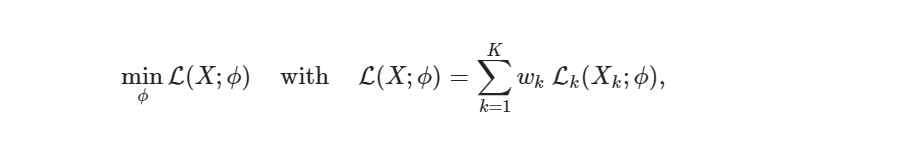
where wk > 0 denote the respective weight coefficients.
In practice, each participant typically obtains and refines a global consensus model by conducting a few rounds of optimisation locally and before sharing updates, either directly or via a parameter server. The more rounds of local training are performed, the less it is guaranteed that the overall procedure is minimising. The actual process for aggregating parameters depends on the network topology.
Nota: that aggregation strategies do not necessarily require information about the full model update
Different types of FL
FL solutions can be classified according to the way they allow data to be aggregated, according to the network topology and finally how different datasets are used.
Broadly, there are three types of gad bridge:
- Intra-company: Bridging internal data silos.
- Inter-company: Facilitating collaboration between organizations.
- Edge computing: Learning across thousands of edge devices.
FL design choices / Topologies
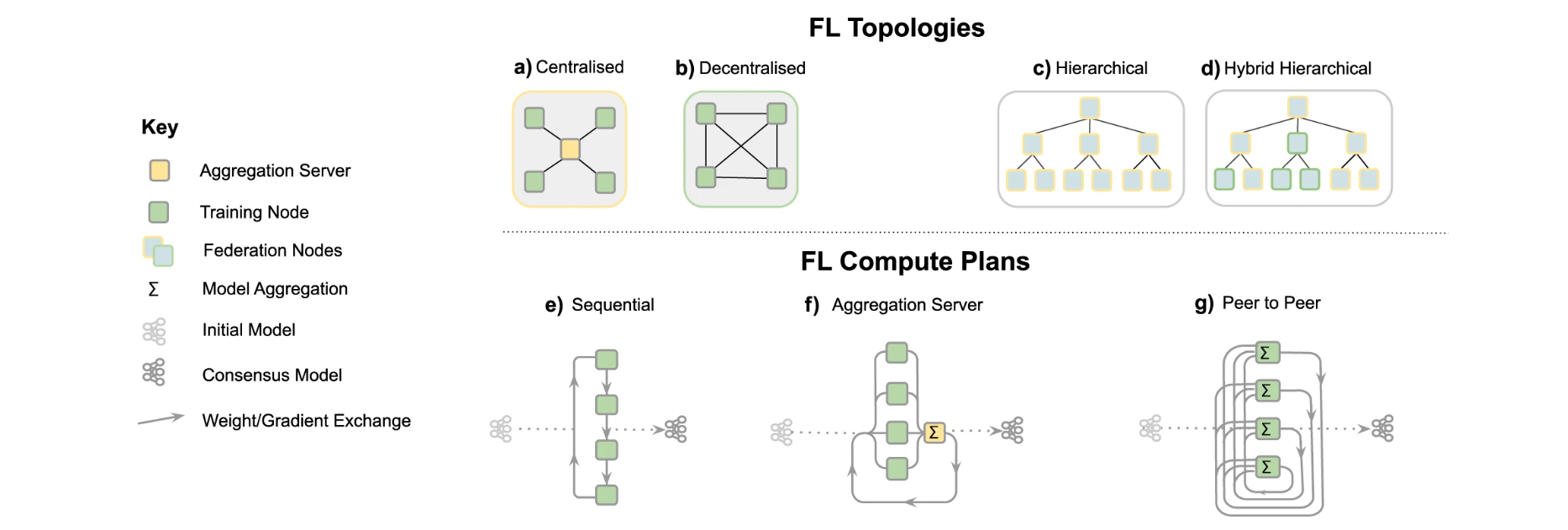
Different communication architectures:
- (a) Centralised: the aggregation server coordinates the training iterations and collects, aggregates and distributes the models to and from the Training Nodes (Hub & Spoke).
- (b) Decentralised: each training node is connected to one or more peers and aggregation occurs on each node in parallel.
- (c) Hierarchical: federated networks can be composed from several sub-federations, which can be built from a mix of Peer to Peer and Aggregation Server federations (d). FL compute plans—trajectory of a model across several partners.
- (e) Sequential training/cyclic transfer learning.
- (f) Aggregation server,
- (g) Peer to Peer.
Vertical & Horizontal FL
This distributed, decentralized training process comes in three flavors. In horizontal federated learning, the central model is trained on similar datasets. In vertical federated learning, the data are complementary; movie and book reviews, for example, are combined to predict someone’s music preferences. Finally, in federated transfer learning, a pre-trained foundation model designed to perform one general task, is trained on another dataset to do something else to repurpose it.
Let’s take the example of two banks from the same country. Although they have non-overlapping clientele, their data will have similar feature spaces since they have very similar business models. They might come together to collaborate in an example of horizontal federated learning.
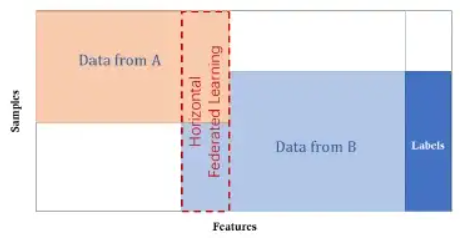
“[…] Horizontal Fl (or sample-based FL / homogenous FL), is introduced in the scenarios that data sets share the same feature space but different in samples.”
In vertical federated learning, two companies providing different services (e.g. banking and e-commerce) but having a large intersection of clientele might find room to collaborate on the different feature spaces they own, leading to better outcomes for both.
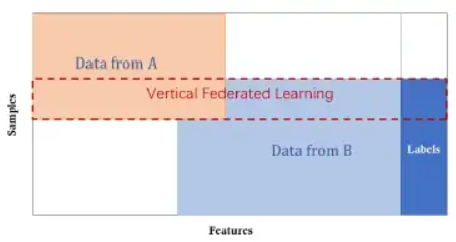
“[…] Vertical FL (or feature-based FL) is applicable to the cases that two data sets share the same sample ID space but differ in feature space.”
Federated Transfer Learning: To my knowledge, there isn’t any concrete production implementation yet, because transfer learning is already used widely without the need of decentralization, but one might consider the advantage of more datas…
Open source frameworks
- FATE
- Substra
- OpenMined’s PyGrid & PySyft
- OpenFL
- TensorFlow Federated
- Flower: A Friendly FL Framework
- IBM Federated Learning
- NVIDIA Clara
- Enterprise-grade Federated Learning Platforms
I haven’t tested those frameworks myself, so it wouldn’t be possible to create an objective benchmark. Moreover things are moving rapidly… But it’s obviously in the interest of cloud providers to make such frameworks robust and secure in order to create an hybrid architecture able to comminucate with on-premise nodes.
Applications / Examples
- FL was first introduced by Google in 2017 to improve text prediction in mobile keyboard
- Due to Covid19, one of the biggest real-world federated collaborations, involved 20 distinct hospitals from five different continents training an AI model to forecast the oxygen requirements of patients with COVID-19.

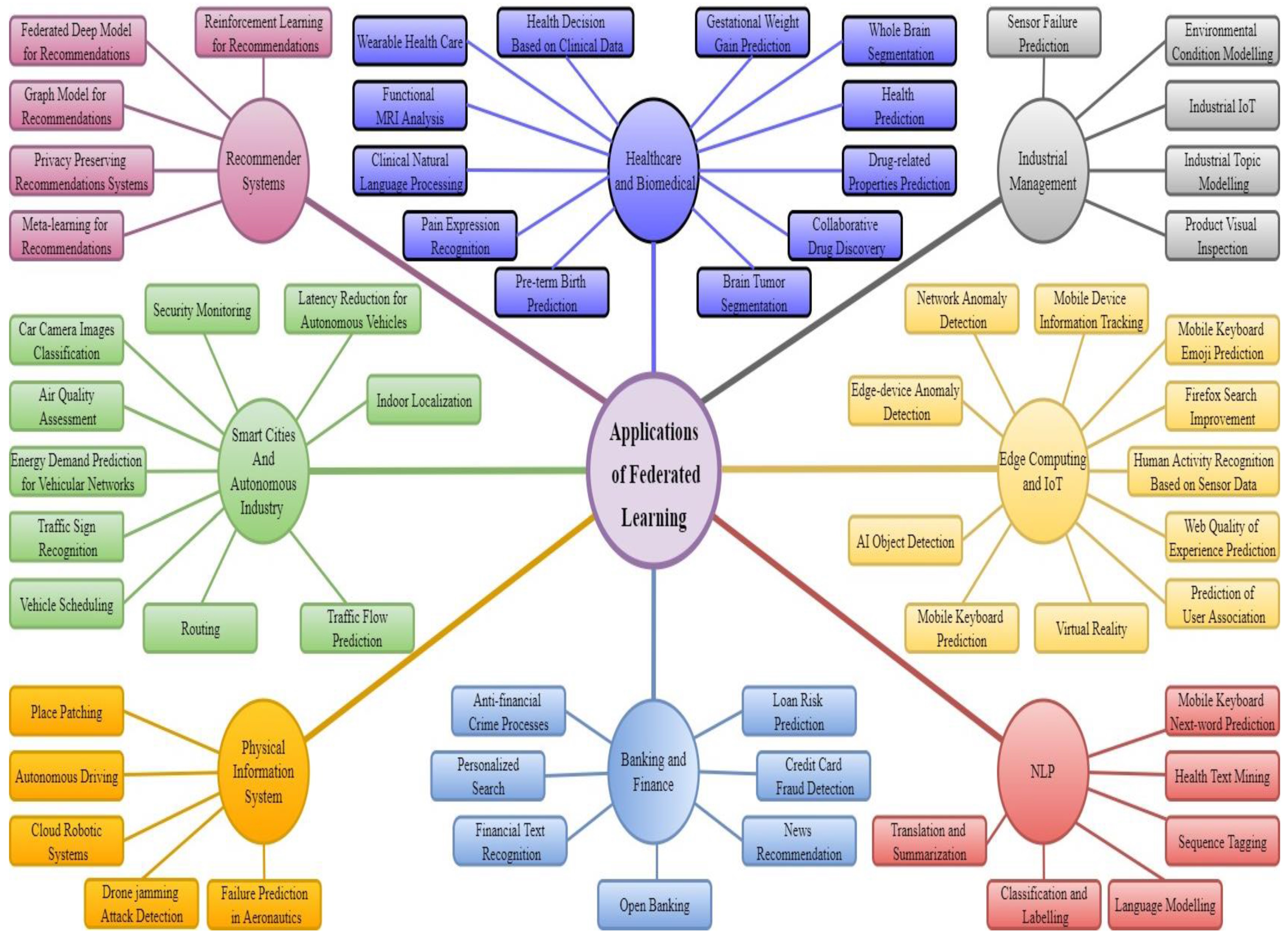
There are many more domains of interest such as robotics, finance (credit scoring, risk prediction & prevention, get a user’s digital footprint that will help to prevent fraud, KYC without transferring data to the cloud), recommender systems, and call center analytics.
Taxonomy for applications of federated learning across different domains and sub-domains:
Challenges & considerations
The clients involved in federated learning may be unreliable as they are subject to more failures or drop out since they commonly rely on less powerful communication media (i.e. Wi-Fi) and battery-powered systems (i.e. smartphones and IoT devices)
Same old issues
Despite the advantages of FL, it does not solve all issues: particularly the same data quality problems
Expensive Communication:
Federated networks are potentially comprised of a massive number of devices (e.g., millions of smart phones), and communication in the network can be slower than local computation by many orders of magnitude. Communication in such networks can be much more expensive than that in classical data center environments. In order to fit a model to data generated by the devices in a federated network, it is therefore necessary to develop communication-efficient methods that iteratively send small messages or model updates as part of the training process, as opposed to sending the entire dataset over the network.
Data heterogeneity
Inhomogeneous data distribution poses a challenge for FL algorithms and strategies, as many are assuming IID (independent & non-identically distributed): the assumption of iid variables is central to many statistical methods & algorithms and can add complexity or cause problems to the model.
Leakage or attacks
FL can indirectly expose private data used for local training, e.g., by model inversion of the model updates, the gradients themselves or adversarial attacks
Through reverse engineering, it’s still possible to identify and obtain the data from a specific user. However, privacy techniques such as differential privacy can strengthen the privacy of federated learning but at the cost of lower model accuracy.
Traceability and accountability
Traceability of all system assets including data access history, training configurations, and hyperparameter tuning throughout the training processes is thus mandatory.
It may also be helpful to measure the amount of contribution from each participant, such as computational resources consumed, quality of the data used for local training, etc.
Systems Heterogeneity
The storage, computational, and communication capabilities of each device in federated networks may differ due to variability in hardware (CPU, memory), network connectivity (3G, 4G, 5G, wifi), and power (battery level). Additionally, the network size and systems-related constraints on each device typically result in only a small fraction of the devices being active at once. For example, only hundreds of devices may be active in a million-device network. Each device may also be unreliable, and it is not uncommon for an active device to drop out at a given iteration. These system-level characteristics make issues such as stragglers and fault tolerance significantly more prevalent than in typical data center environments. There will be a tradeoff between maintaining the performance of the device and model accuracy.
Final thoughts
FL has many benefits as it enhances user data privacy, its adherence with regulatory compliance, and its ability to break silos, but on the other had there are still many technical limitations, and there is a lot of work for competing companies to be on the same page in the way to create and use the same federated network…
Despite the fact that FL requires rigorous technical consideration to ensure that the algorithm is proceeding optimally without compromising safety or patient privacy. Nevertheless, it has the potential to overcome some limitations of approaches that require a single pool of centralised data.
A still open question at the moment is how inferior models learned through federated data are relative to ones where the data are pooled. Another open question concerns the trustworthiness of the edge devices and the impact of malicious actors on the learned model.
“Keeping data private is the major value addition of FL for each of the participating entities to achieve a common goal.”
FL enables collaborative research for, even competing, companies, it might give birth to a new data ecosystem and create data alliances.
“FL can be paired with other privacy-preserving techniques like differential privacy to add noise and homomorphic encryption to encrypt model updates and obscure what the central server sees.”
Credits & References:
As previously said, this post is an aggregation of multiples sources, it is hard to give credits precisely for each part, it is widely inspired by the Nature presentation “The future of digital health with federated learning - Nature” and by this Wikipedia webpage. I would like to warmly thanks the authors. Credits should also be given for the following references:
General blog posts:
- Introduction to Federated Learning - Medium
- Federated machine learning for fintech. - Medium
- What is federated learning? - IBM
- Understanding the types of FL
- Federated Learning — Decentralized ML
- Federated Learning: The Shift from Centralized to Distributed On-Device Model Training
- A brief introduction to Federated Learning — FL Series Part 1
Technical papers / insights:
- Using Federated Learning to Bridge Data Silos in Financial Services - Nvidia
- Top 7 Open-Source Frameworks for Federated Learning - Apheris
- A Secure Federated Transfer LearningFramework
- Federated Learning: Challenges, Methods, and Future Directions
FL applications:
- Federated Learning: A New AI Business Model - Medium
- Federated learning for predicting clinical outcomes in patients with COVID-19
Misc :)