

H&M Personalized Fashion 2/2 - Recommendation system
Banner made from a photo by Tembela Bohle on pexels
Introduction
In the 1st part of this project we’ve analyzed in depth the different available datasets. Now, in this second and final step we’re going to build a product recommendations system based on data from previous transactions, by using the LightFM python library.
!pip install lightfm
As usual let’s import all that we need:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import itertools
import pickle
import os
from scipy import sparse
from lightfm import LightFM
from lightfm.data import Dataset
from lightfm.cross_validation import random_train_test_split
from lightfm.evaluation import precision_at_k, recall_at_k, auc_score
pd.set_option('mode.chained_assignment', None)
RANDOM_STATE = 42
ENV = "COLAB" # "LOCAL" #
if ENV == "COLAB":
from google.colab import drive
drive.mount('/content/drive')
dir_path = "drive/MyDrive/recomm/projet/"
else:
dir_path = "../../../dataset/"
file_customers = "customers.csv"
file_articles = "articles.csv"
file_transactions = "transactions_train.csv"
df_customers = pd.read_csv(dir_path + file_customers)
df_articles = pd.read_csv(dir_path + file_articles)
df_transactions = pd.read_csv(dir_path + file_transactions)
What is LightFM?
It’s a hybrid matrix factorisation model representing users and items as linear combinations of their content features’ latent factors. The model seems to outperforms both collaborative and content-based models in cold-start or sparse interaction data scenarios (using both user and item metadata), and performs at least as well as a pure collaborative matrix factorisation model where interaction data is abundant.
In LightFM, like in a collaborative filtering model, users and items are represented as latent vectors (embeddings). However, just as in a CB model, these are entirely defined by functions (in this case, linear combinations) of embeddings of the content features that describe each product or user.
How LightFM works?
The LightFM paper describes its inner working: a lightFM model learns embeddings (latent representations in a high-dimensional space) for users and items in a way that encodes user preferences over items. When multiplied together, these representations produce scores for every item for a given user; items scored highly are more likely to be interesting to the user.
Data Preparation
For recommendation models, we have to deal with sparse datasets. Here we’re going to keep a subset as dense as possible, by keeping only one full year (2019) of transactions:
assert df_articles.article_id.nunique() == df_articles.shape[0]
Hands-On Machine Learning with Scikit-Learn and TensorFlow
print(f"Nb of transactions before filtering: {df_transactions.shape[0]}")
df_transactions.t_dat = pd.to_datetime(df_transactions.t_dat, infer_datetime_format=True)
df = df_transactions[(df_transactions.t_dat.dt.year == 2019)] # & (df_transactions.t_dat.dt.month.isin([5, 6, 7]))] # DEBUG
print(f"Nb of transactions after filtering: {df.shape[0]}")
df = df.merge(df_articles[["article_id", "index_group_name", "index_name", "section_name"]], on='article_id')
# del df_articles
# df = df.merge(df_customers, on='customer_id') # not needed
# del df_customers
f"Total Memory Usage: {df.memory_usage(deep=True).sum() / 1024**2:.2f} MB"
Nb of transactions before filtering: 31788324
Nb of transactions after filtering: 5274015
'Total Memory Usage: 1870.28 MB'
We keep only customers with at least 10 transactions, and drop customers with more than 100 purchases (resellers):
customers_count = df['customer_id'].value_counts()
customers_count[(customers_count > 10) & (customers_count < 50)].shape
(154282,)
We also filter customer_id aged above 38 as it seems to be one of the target of H&M according to our EDA:
df_customers.customer_id.nunique(), df_customers[(df_customers.age > 16) & (df_customers.age < 38)].customer_id.nunique(),
(1371980, 803696)
print(f"Nb of customers before filtering: {df.customer_id.nunique()} and nb_transactions {df.shape[0]}")
customers_count = df['customer_id'].value_counts()
# 1st selection based on the nb of transactions
customers_kept = customers_count[(customers_count > 10) & (customers_count < 100)].index.values
df = df[df.customer_id.isin(customers_kept)]
# 2nd selection based on the customers' ages
customers_kept = df_customers[(df_customers.age > 16) & (df_customers.age < 38)].customer_id.unique()
df = df[df.customer_id.isin(customers_kept)]
print(f"Nb of customers after filtering: {df.customer_id.nunique()} and nb_transactions {df.shape[0]}")
f"Total Memory Usage: {df.memory_usage(deep=True).sum() / 1024**2:.2f} MB"
Nb of customers before filtering: 559625 and nb_transactions 5274015
Nb of customers after filtering: 99603 and nb_transactions 2127829
'Total Memory Usage: 754.88 MB'
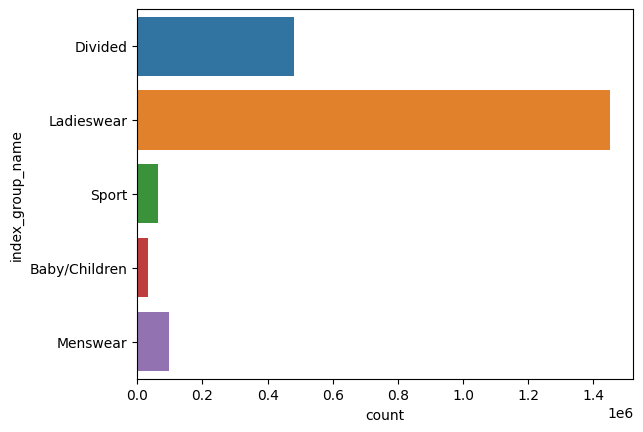
For the sake of simplicity (and because training recommendation models on huge amount of data required many computation ressources), we’re also going to keep only the main clothes’ target: “Ladieswear”
sns.countplot(y=df["index_group_name"])
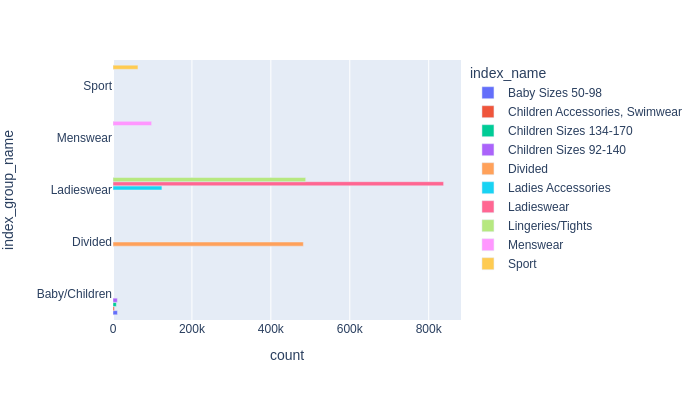
df_temp = df.groupby(["index_group_name", "index_name"]).count()['t_dat'].reset_index().rename(columns={"t_dat": "count"})
px.bar(
df_temp, x="count", y="index_group_name",
color='index_name', barmode='group',
width=700, height=400
).show()
For now, we’re not going to use the items features. Usually, the customers informations are more used for marketing purpose rather than features for the recommendation model. At the end, the dataset is only composed of customer_id & article_id, with many duplicated rows when items are purchased multiple times:
df = df.loc[df.index_name == "Ladieswear"]
# if we want to restore the original dataset without loading it again
df_backup = df.copy()
df.drop(columns=[
't_dat',
'price',
'sales_channel_id',
'index_group_name',
'index_name',
'section_name'], inplace=True)
print(df.shape)
print(df.customer_id.nunique(), df.article_id.nunique())
df.head()
(837769, 2)
92444 10962
| customer_id | article_id | |
|---|---|---|
| 119 | 2d204c6e1ada9b80883dbb539a5048e72280289be7024f... | 735404001 |
| 120 | 2f3d8fc02d513e39f120a142bf1f5004f08f726343b60a... | 735404001 |
| 122 | 3550bfadda83a32d8e0526ca4d26f8bf9a391e2ea16bd5... | 735404001 |
| 123 | 36ecdd962d8a50a0a12a65f1087457d2ac7757265dd199... | 735404001 |
| 124 | 3d1231f8cfeb6390fb5379ae48a9a73095d2bc9fb22ab0... | 735404001 |
Feedback matrix
Firstly, we have to create lightFM Dataset for our model. LightFM Dataset class makes it really easy for us for creating interection matrix, weights and user/item features.
interection matrix: It is a matrix that contains user/ item interections or professional/quesiton intereactions.weights: weight of interection matrix. Less weight means less importance to that interection matrix.user/item features: user/item features supplied as like this (user_id, [‘feature_1’, ‘feature_2’, ‘feature_3’])
The LightFM libary can only be trained on sparse matrix: this is the types of dataset return by the build_interactions method based on our initial dataset:
dataset = Dataset()
# mapping creation
dataset.fit(
users=df.customer_id.unique(),
items=df.article_id.unique(),
user_features=None,
item_features=None
)
interactions, weights = dataset.build_interactions([(x[0], x[1]) for x in df.values])
int_dense = interactions.todense()
print(int_dense.shape)
int_dense
(92444, 10962)
matrix([[1, 0, 0, ..., 0, 0, 0],
[1, 0, 0, ..., 0, 0, 0],
[1, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=int32)
Split dataset
Let’s create separated train and test datasets:
train, test = random_train_test_split(
interactions = interactions,
test_percentage = 0.2,
random_state = np.random.RandomState(seed=RANDOM_STATE)
)
train.todense().shape, test.todense().shape
((92444, 10962), (92444, 10962))
Recommendation systems
Recommender Systems are powerful, successful and widespread applications for almost every business selling products or services. It’s especially useful for companies with a wide offer and diverse clients. Ideal examples are retail companies as well as these selling services or digital products.
You’ll notice that after creating an account on Netflix or Spotify for example, the service will start to recommend you other products, movies or songs that the algorithm thinks will suit you the best. It’s their way to personalise the offer and who doesn’t like to get such care. That’s why these systems are precious for business owners. The more you buy, watch and listen the better it gets. Also, the more users the better it gets.
Recommender Systems usually are classified into three groups:
- Collaborative-filtering:
Collaborative filtering is a method of making automatic predictions (filtering) about the interests of a user by collecting preferences or taste information from many users (collaborating). The underlying assumption of the collaborative filtering approach is that if a person A has the same opinion as a person B on an issue, A is more likely to have B’s opinion on a different issue than that of a randomly chosen person.
Though collaborative filtering One major problem of collaborative filtering is “cold start”. As we’ve seen, collaborative-filtering can be a powerful way of recommending items based on user history, but what if there is no user history? This is called the “cold start” problem, and it can apply both to new items and to new users. Items with lots of history get recommended a lot, while those without never make it into the recommendation engine, resulting in a positive feedback loop. At the same time, new users have no history and thus the system doesn’t have any good recommendations. Potential solution: Onboarding processes can learn basic info to jump-start user preferences, importing social network contacts.
- Content-based filtering
These filtering methods are based on the description of an item and a profile of the user’s preferred choices. In a content-based recommendation system, keywords are used to describe the items; besides, a user profile is built to state the type of item this user likes. In other words, the algorithms try to recommend products which are similar to the ones that a user has liked in the past. The idea of content-based filtering is that if you like an item you will also like a ‘similar’ item. For example, when we are recommending the same kind of item like a movie or song recommendation.
One major problem of this approach is the diversity. Relevance is important, but it’s not all there is. If you watched and liked Star Wars, the odds are pretty good that you’ll also like The Empire Strikes Back, but you probably don’t need a recommendation engine to tell you that. It’s also important for a recommendation engine to come up with results that are novel (that is, stuff the user wasn’t expecting) and diverse (that is, stuff that represents a broad selection of their interests).
- Hybrid recommender system:
Hybrid recommender system is a special type of recommender system that combines both content and collaborative filtering method. Combining collaborative filtering and content-based filtering could be more effective in some cases. Hybrid approaches can be implemented in several ways: by making content-based and collaborative-based predictions separately and then combining them; by adding content-based capabilities to a collaborative-based approach (and vice versa). Several studies empirically compare the performance of the hybrid with pure collaborative and content-based methods and demonstrate that hybrid methods can provide more accurate recommendations than pure approaches. These methods can also be used to overcome some of the common problems in recommender systems such as cold start and the sparsity problem.
Building models with LightFM
We start building our LightFM model using LightFM class. LightFM class makes it really easy for making lightFM model. After that we will fit our model on our train dataset.
Baseline
model = LightFM(
no_components=50,
learning_rate=0.05,
loss='warp',
random_state=RANDOM_STATE)
model.fit(
train,
item_features=None,
user_features=None,
sample_weight=None,
epochs=5,
num_threads=4,
verbose=True
)
Epoch: 100%|██████████| 5/5 [00:10<00:00, 2.17s/it]
<lightfm.lightfm.LightFM at 0x7ca41bcb2f20>
Evaluation
Evaluation metrics to consider:
- AUC : It measure the ROC AUC metric for a model: the probability that a randomly chosen positive example has a higher score than a randomly chosen negative example. A perfect score is 1.0.
- Precision at K : Measure the precision at k metric for a model: the fraction of known positives in the first k positions of the ranked list of results.A perfect score is 1.0.
- Recall at K : Measure the recall at k metric for a model: the number of positive items in the first k positions of the ranked list of results divided by the number of positive items in the test period. A perfect score is 1.0.
- Mean Reciprocal rank : Measure the reciprocal rank metric for a model: 1 / the rank of the highest ranked positive example. A perfect score is 1.0.
Here we’re going to use the preicision at k:
precision_train = precision_at_k(model, train, k=10, num_threads=4).mean()
precision_test = precision_at_k(model, test, k=10, num_threads=4).mean()
# recall_train = recall_at_k(model, train, k=10).mean()
# recall_test = recall_at_k(model, test, k=10).mean()
print(precision_train, precision_test)
0.17519069 0.024261154
Hyperparameter Tuning using Random Search
Taken from this blog post with adjustments to include or not the weights.
Side note: usually it’s better to perfom hyperparameter tuning on a validation dataset using k-folds.
def sample_hyperparameters():
while True:
yield {
"no_components": np.random.randint(16, 64),
"learning_schedule": np.random.choice(["adagrad", "adadelta"]),
"loss": np.random.choice(["bpr", "warp", "warp-kos"]),
"learning_rate": np.random.exponential(0.05),
"item_alpha": np.random.exponential(1e-8),
"user_alpha": np.random.exponential(1e-8),
"max_sampled": np.random.randint(5, 15),
"num_epochs": np.random.randint(5, 50),
}
def random_search(train_interactions, test_interactions, num_samples=50, num_threads=1, weights=None):
for hyperparams in itertools.islice(sample_hyperparameters(), num_samples):
num_epochs = hyperparams.pop("num_epochs")
model = LightFM(**hyperparams)
model.fit(
interactions,
item_features=None,
user_features=None,
sample_weight=weights,
epochs=num_epochs,
num_threads=num_threads,
verbose=True
)
score = precision_at_k(
model=model,
test_interactions=test,
train_interactions=None,
k=10,
num_threads=num_threads
).mean()
weights_ = "No" if weights is None else "Yes"
print(f"score: {score:.4f}, weights: {weights_}, hyperparams: {hyperparams}")
hyperparams["num_epochs"] = num_epochs
yield (score, hyperparams, model)
optimized_dict={}
score, hyperparams, model = max(random_search(
train_interactions = train,
test_interactions = test,
num_threads = 4
), key=lambda x: x[0])
print(f"WITHOUT WEIGHTS: best score {score} obtained with the following hyper parameters {hyperparams}")
with open(dir_path + 'model_without_weights.pkl', 'wb') as f:
pickle.dump(model, f)
Epoch: 100%|██████████| 20/20 [01:16<00:00, 3.81s/it]
score: 0.1184, weights: No, hyperparams: {'no_components': 60, 'learning_schedule': 'adadelta', 'loss': 'warp-kos', 'learning_rate': 0.008489458350985983, 'item_alpha': 5.2786918388645496e-11, 'user_alpha': 3.5578101760199264e-08, 'max_sampled': 8}
Epoch: 100%|██████████| 15/15 [00:28<00:00, 1.91s/it]
score: 0.0157, weights: No, hyperparams: {'no_components': 26, 'learning_schedule': 'adagrad', 'loss': 'bpr', 'learning_rate': 0.011351236451160842, 'item_alpha': 2.3757447922172716e-09, 'user_alpha': 2.576221612240835e-08, 'max_sampled': 8}
[...]
Epoch: 100%|██████████| 44/44 [02:46<00:00, 3.79s/it]
score: 0.1304, weights: No, hyperparams: {'no_components': 54, 'learning_schedule': 'adadelta', 'loss': 'warp-kos', 'learning_rate': 0.009802596101768535, 'item_alpha': 1.1405022588283016e-08, 'user_alpha': 1.1784362838916816e-08, 'max_sampled': 11}
Epoch: 100%|██████████| 43/43 [01:38<00:00, 2.30s/it]
score: 0.0916, weights: No, hyperparams: {'no_components': 46, 'learning_schedule': 'adagrad', 'loss': 'bpr', 'learning_rate': 0.030843895830248953, 'item_alpha': 8.392851304125428e-09, 'user_alpha': 1.0179184395176035e-08, 'max_sampled': 13}
WITHOUT WEIGHTS: best score 0.13038481771945953 obtained with the following hyper parameters {'no_components': 54, 'learning_schedule': 'adadelta', 'loss': 'warp-kos', 'learning_rate': 0.009802596101768535, 'item_alpha': 1.1405022588283016e-08, 'user_alpha': 1.1784362838916816e-08, 'max_sampled': 11, 'num_epochs': 44}
So, without considering the weights (i.e the number of times an itmen is bought by the same customer), the best precision score 0.13 on the test set, obtained with the following hyper parameters:
- no_components: 54
- learning_schedule: ‘adadelta’
- learning_rate’: 0.0098
- item_alpha: 1.14e-08
- user_alpha: 1.17e-08
- max_sampled’: 11
- num_epochs: 44
Using Weights
Let’s try the same thing but this time with the weights:
# overriden because the k-OS loss with sample weights is not implemented.
def sample_hyperparameters():
while True:
yield {
"no_components": np.random.randint(16, 64),
"learning_schedule": np.random.choice(["adagrad", "adadelta"]),
"loss": np.random.choice(["bpr", "warp"]), #, "warp-kos"]),
"learning_rate": np.random.exponential(0.05),
"item_alpha": np.random.exponential(1e-8),
"user_alpha": np.random.exponential(1e-8),
"max_sampled": np.random.randint(5, 15),
"num_epochs": np.random.randint(5, 50),
}
score_w, hyperparams_w, model_w = max(random_search(
train_interactions = train,
test_interactions = test,
num_threads = 4,
weights=weights,
), key=lambda x: x[0])
print(f"WITH WEIGHTS: best score {score_w} obtained with the following hyper parameters {hyperparams_w}")
with open(dir_path + 'model_with_weights.pkl', 'wb') as f:
pickle.dump(model_w, f)
Epoch: 100%|██████████| 21/21 [00:36<00:00, 1.74s/it]
score: 0.0658, weights: Yes, hyperparams: {'no_components': 35, 'learning_schedule': 'adagrad', 'loss': 'warp', 'learning_rate': 0.03793522958313662, 'item_alpha': 1.526228884795337e-09, 'user_alpha': 1.4820473052576738e-08, 'max_sampled': 10}
Epoch: 100%|██████████| 41/41 [00:59<00:00, 1.44s/it]
score: 0.0558, weights: Yes, hyperparams: {'no_components': 35, 'learning_schedule': 'adagrad', 'loss': 'warp', 'learning_rate': 0.020399551978036737, 'item_alpha': 2.462376731983936e-08, 'user_alpha': 4.266936687426811e-09, 'max_sampled': 6}
[...]
Epoch: 100%|██████████| 27/27 [00:47<00:00, 1.74s/it]
score: 0.0537, weights: Yes, hyperparams: {'no_components': 19, 'learning_schedule': 'adadelta', 'loss': 'bpr', 'learning_rate': 0.08636897698001998, 'item_alpha': 4.230409864246658e-10, 'user_alpha': 3.649947540870082e-08, 'max_sampled': 7}
Epoch: 100%|██████████| 15/15 [00:31<00:00, 2.11s/it]
score: 0.0630, weights: Yes, hyperparams: {'no_components': 42, 'learning_schedule': 'adagrad', 'loss': 'bpr', 'learning_rate': 0.03273940087847153, 'item_alpha': 3.791919344957527e-09, 'user_alpha': 2.02930754839095e-08, 'max_sampled': 14}
WITH WEIGHTS: best score 0.11721404641866684 obtained with the following hyper parameters {'no_components': 62, 'learning_schedule': 'adadelta', 'loss': 'bpr', 'learning_rate': 0.005779964110324431, 'item_alpha': 5.8232841799619904e-09, 'user_alpha': 1.7112869692085306e-09, 'max_sampled': 10, 'num_epochs': 34}
The best precision score on the test set is 0.117, which unfortunately not better.
Predictions
To get recommendation for a particular customer, we can use the predict method and the different mappings, that way we can also have the score :
user_id_mapping, user_feature_mapping, item_id_mapping, item_feature_mapping = dataset.mapping()
n_users, n_items = df.customer_id.nunique(), df.article_id.nunique()
def get_top_k_recommendations_with_scores(customer_id, k=10):
item_id_mapping_reverse = {v:k for k, v in item_id_mapping.items()}
# the top recommendation is the item with the highest predict score, not the lowest.
recommendation_scores_for_pairs = model.predict(user_id_mapping[customer_id], np.arange(n_items))
recommendations = pd.DataFrame({"scores": recommendation_scores_for_pairs})
recommendations["article_id"] = pd.Series(recommendations.index.values).apply(lambda x: item_id_mapping_reverse[x])
recommendations = recommendations.merge(df_articles[["article_id", "prod_name", "product_type_name"]], on="article_id")
display(recommendations.sort_values(by="scores", ascending=False).head(k))
get_top_k_recommendations_with_scores('c88e095d490d67ba66f57132759057247040570935ba21a447e64b782d20880c')
| scores | article_id | prod_name | product_type_name | |
|---|---|---|---|---|
| 7660 | 2.849209 | 752981001 | Sara single | T-shirt |
| 728 | 2.624799 | 433444001 | Sara s/s 2-pack | T-shirt |
| 4416 | 2.557556 | 300024013 | Superskinny | Trousers |
| 2755 | 2.545403 | 510465001 | Moa 2-pack | Vest top |
| 966 | 2.459155 | 262277011 | Kim superskinny low waist | Trousers |
| 1770 | 2.458308 | 590071010 | Mika SS | T-shirt |
| 2075 | 2.447792 | 469562002 | Skinny denim (1) | Trousers |
| 4937 | 2.422281 | 510074015 | Barza | Trousers |
| 3070 | 2.410026 | 691479002 | Love shorts | Shorts |
| 1981 | 2.409466 | 433444017 | Sara s/s 2-pack | T-shirt |
It also is possible to use the predict_rank method on a whole dataset:
ranks = model.predict_rank(
test_interactions=test,
train_interactions=None,
item_features=None,
user_features=None,
num_threads=4,
check_intersections=True
)
ranks_dense = ranks.todense()
assert ranks_dense.shape == (df.customer_id.nunique(), df.article_id.nunique())
