

Historical consumption regression for electricity supply pricing - part 1/2
Photo by israel palacio on Unsplash
Introduction
Context
- Planete OUI offers green electricity supply with prices adapted to the consumption profiles of its clients.
- The electricity prices are highly variable during time (depending on the market, the global consumption and its client needs).
- The consumption profile of an installation has to be appraised to compute the best estimation of supply tarifs
- Most sites have a consumption varying strongly with temperature because of electrical heating systems.
- Except industrial installations because their consumption might be highly related their uses
The 1st objectives are to analyze thermosensitivity uses and / or other factors (times series…) affecting consumption
Based on:
- the potential client historical consumption data (i.e its profile)
- electricity prices
- a given percentile used to cover supply costs for different scenarios the 2nd objective of Planète OUI is to compute a distribution of supply costs in €/MWh.
Planète OUI needs
Extrapolation of one or several years consumption data rebuilt from a single year of measured data supplied by the client (in order to be Tcombined with electricity prices) and to get a larger data set of analysis.
Data
- The client’s data is often incomplete and spread over a relatively short period.
- 3 datasets:
- x_train : input data of the training set
- y_train : output data of the training set
- x_test : input data of the testing set
- Features:
- “ID”: Data point ID;
- “timestamp”: Complete timestamps with year, month, day and hour, in local time (CET and CEST);
- “temp1”, “temp2”, “meannationaltemp”: Local and mean national temperatures (°C);
- “humidity1”, “humidity2”: Local relative humidities (%);
- “loc1”, “loc2” “locsecondary1”, “locsecondary2”, “locsecondary3”: the coordinates of the studied and secondary sites, in decimal degrees and of the form (latitude, longitude).
- “consumptionsecondary1”, “consumptionsecondary2”, “consumptionsecondary3”: the consumption data of three secondary sites, whose correlations with studied sites may be of use (kWh). Indeed, the two studied sites and the three secondary sites are used for the same purposes; The output data of the model to be developed takes the following form:
- “ID”: Data point ID;
- “consumption1”, “consumption2”: the consumption data of the two studied sites (kWh).
Relative humidities are provided with temperature data because they represent variables of importance for electricity consumption: humidity indeed strongly available for all. It has influences thermal comfort. To replicate operational conditions, some temperature integrated BCM Energy’s and humidity data points will be missing. The imputation method must be carefully perimeter in 2017. considered. The “consumptionsecondaryi” variables are the consumption data of several sites with metering power higher than 250 kVA of the Planète OUIs portfolio.
This correlation of the various sites consumptions shall be studied to precise data completion or interpolation. Timestamps may be expressed as month or day of year, day of week and hours, to study the impact of annual, weekly and daily seasonalities. Particular attention should be paid to national holidays processing.
Challenge goal
Prediction of the consumption of two given sites during a year, based on measured data of other profiles.
First data insight
Basic infos
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
pd.set_option('display.max_columns', 100)
from sklearn.preprocessing import MinMaxScaler
import folium
input_dir = os.path.join('..', 'input')
output_dir = os.path.join('..', 'output')
print(os.listdir(input_dir))
['input_training_ssnsrY0.csv', 'Screenshot from 2019-05-28 10-48-59.png', 'input_test_cdKcI0e.csv', 'vacances-scolaires.csv', 'jours_feries_seuls.csv', 'BCM_custom_metric.py', 'output_training_Uf11I9I.csv']
# each id is unique so we can use this column as index
df = pd.read_csv(os.path.join(input_dir, 'input_training_ssnsrY0.csv'), index_col='ID')
df.iloc[23:26]
| timestamp | temp_1 | temp_2 | mean_national_temp | humidity_1 | humidity_2 | loc_1 | loc_2 | loc_secondary_1 | loc_secondary_2 | loc_secondary_3 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | ||||||||||||||
| 23 | 2016-11-01T23:00:00.0 | 10.8 | NaN | 11.1 | 87.0 | NaN | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 143 | 67 | 162 |
| 24 | 2016-11-02T00:00:00.0 | 10.8 | NaN | 11.1 | 86.0 | NaN | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 144 | 75 | 161 |
| 25 | 2016-11-02T01:00:00.0 | 10.5 | NaN | 11.0 | 81.0 | NaN | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 141 | 65 | 161 |
df_out = pd.read_csv(os.path.join('..', 'input', 'output_training_Uf11I9I.csv'), index_col='ID')
df_out.head()
| consumption_1 | consumption_2 | |
|---|---|---|
| ID | ||
| 0 | 100 | 93 |
| 1 | 101 | 94 |
| 2 | 100 | 96 |
| 3 | 101 | 95 |
| 4 | 100 | 100 |
df.shape, df_out.shape
((8760, 14), (8760, 2))
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 8760 entries, 0 to 8759
Data columns (total 14 columns):
timestamp 8760 non-null object
temp_1 8589 non-null float64
temp_2 8429 non-null float64
mean_national_temp 8760 non-null float64
humidity_1 8589 non-null float64
humidity_2 8428 non-null float64
loc_1 8760 non-null object
loc_2 8760 non-null object
loc_secondary_1 8760 non-null object
loc_secondary_2 8760 non-null object
loc_secondary_3 8760 non-null object
consumption_secondary_1 8760 non-null int64
consumption_secondary_2 8760 non-null int64
consumption_secondary_3 8760 non-null int64
dtypes: float64(5), int64(3), object(6)
memory usage: 1.0+ MB
Missing or irrelevant values
df.isnull().sum()
timestamp 0
temp_1 171
temp_2 331
mean_national_temp 0
humidity_1 171
humidity_2 332
loc_1 0
loc_2 0
loc_secondary_1 0
loc_secondary_2 0
loc_secondary_3 0
consumption_secondary_1 0
consumption_secondary_2 0
consumption_secondary_3 0
dtype: int64
df.duplicated().sum()
0
#sns.pairplot(df_viz.select_dtypes(['int64', 'float64']))#.apply(pd.Series.nunique, axis=0)
Transforming time informations
def transform_datetime_infos(data_frame):
data_frame['datetime'] = pd.to_datetime(data_frame['timestamp'])
data_frame['month'] = data_frame['datetime'].dt.month
data_frame['week of year'] = data_frame['datetime'].dt.weekofyear
data_frame['day of year'] = data_frame['datetime'].dt.dayofyear
data_frame['day'] = data_frame['datetime'].dt.weekday_name
data_frame['hour'] = data_frame['datetime'].dt.hour
# for merging purposes
data_frame['date'] = data_frame['datetime'].dt.strftime('%Y-%m-%d')
return data_frame
df = transform_datetime_infos(df)
df.head(3)
| timestamp | temp_1 | temp_2 | mean_national_temp | humidity_1 | humidity_2 | loc_1 | loc_2 | loc_secondary_1 | loc_secondary_2 | loc_secondary_3 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | datetime | month | week of year | day of year | day | hour | date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | |||||||||||||||||||||
| 0 | 2016-11-01T00:00:00.0 | 8.3 | NaN | 11.1 | 95.0 | NaN | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 143 | 74 | 168 | 2016-11-01 00:00:00 | 11 | 44 | 306 | Tuesday | 0 | 2016-11-01 |
| 1 | 2016-11-01T01:00:00.0 | 8.0 | NaN | 11.1 | 98.0 | NaN | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 141 | 60 | 162 | 2016-11-01 01:00:00 | 11 | 44 | 306 | Tuesday | 1 | 2016-11-01 |
| 2 | 2016-11-01T02:00:00.0 | 6.8 | NaN | 11.0 | 97.0 | NaN | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 142 | 60 | 164 | 2016-11-01 02:00:00 | 11 | 44 | 306 | Tuesday | 2 | 2016-11-01 |
Considered sites
# Number of unique classes in each object column # Check the nb of sites
df.select_dtypes('object').apply(pd.Series.nunique, axis=0)
timestamp 8759
loc_1 1
loc_2 1
loc_secondary_1 1
loc_secondary_2 1
loc_secondary_3 1
day 7
date 365
dtype: int64
for i in ['loc_1', 'loc_2', 'loc_secondary_1', 'loc_secondary_2', 'loc_secondary_3']:
print('site : ', i, 'coordinates : ', df[i][0])
site : loc_1 coordinates : (50.633, 3.067)
site : loc_2 coordinates : (43.530, 5.447)
site : loc_secondary_1 coordinates : (44.838, -0.579)
site : loc_secondary_2 coordinates : (47.478, -0.563)
site : loc_secondary_3 coordinates : (48.867, 2.333)
# Create a map centered at the given latitude and longitude
france_map = folium.Map(location=[47,1], zoom_start=6)
# Add markers with labels
for i in ['loc_1', 'loc_2', 'loc_secondary_1', 'loc_secondary_2', 'loc_secondary_3']:
temp_str = df[i][0].strip('(').strip(')').strip(' ')
temp_str1, temp_str2 = temp_str.split(', ')
folium.Marker([float(temp_str1), float(temp_str2)], popup=None, tooltip=i).add_to(france_map)
# Display the map
display(france_map)
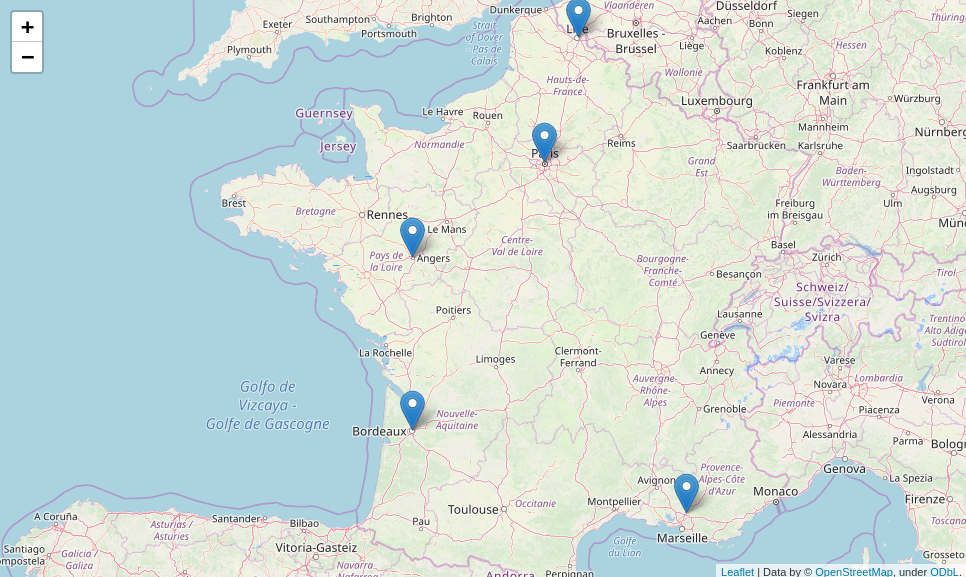
- loc_1 is in the north near Lille.
- loc_1 is in the south east near Marseille.
- loc_secondary_1 is in the south west near Bordeaux.
- loc_secondary_2 is in the west near Le Mans.
- loc_secondary_3 is in the north near Paris.
Exploratory Data Analysis
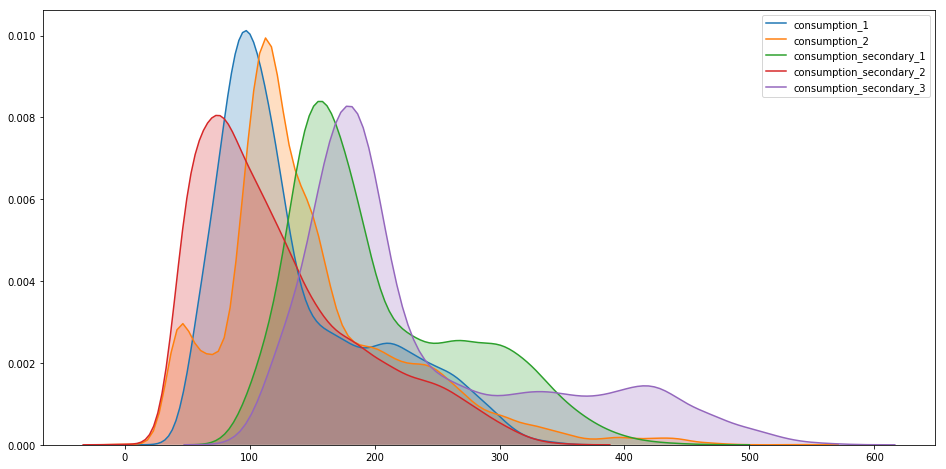
Distribution of consumption
plt.figure(figsize=(16, 8))
sns.kdeplot(df_out['consumption_1'], shade=True) #, label = 'consumption_1')
sns.kdeplot(df_out['consumption_2'], shade=True) #, label = 'consumption_2')
sns.kdeplot(df['consumption_secondary_1'], shade=True) #, label = 'consumption_1')
sns.kdeplot(df['consumption_secondary_2'], shade=True) #, label = 'consumption_1')
sns.kdeplot(df['consumption_secondary_3'], shade=True) #, label = 'consumption_1')
plt.show()
Consumption variation during time
df.groupby(['hour'])['consumption_secondary_1'].mean().values
array([160.77534247, 160.8739726 , 160.5260274 , 160.83835616,
161.46027397, 168.88767123, 191.30136986, 210.9369863 ,
228.49863014, 248.32328767, 256.64657534, 256.21369863,
240.23287671, 238.76438356, 244.09041096, 242.99178082,
237.61643836, 227.66027397, 208.08767123, 195.21917808,
182.35068493, 166.50958904, 161.92054795, 161.87671233])
df_viz = pd.concat((df, df_out), axis=1)
plt.figure(figsize=(16, 8))
plt.title("Consumption Evolution for each site over hours of the day")
for c in ['consumption_1', 'consumption_2', 'consumption_secondary_1', 'consumption_secondary_2', 'consumption_secondary_3']:
sns.lineplot(x="hour", y=c, data=df_viz, label=c)
plt.show()
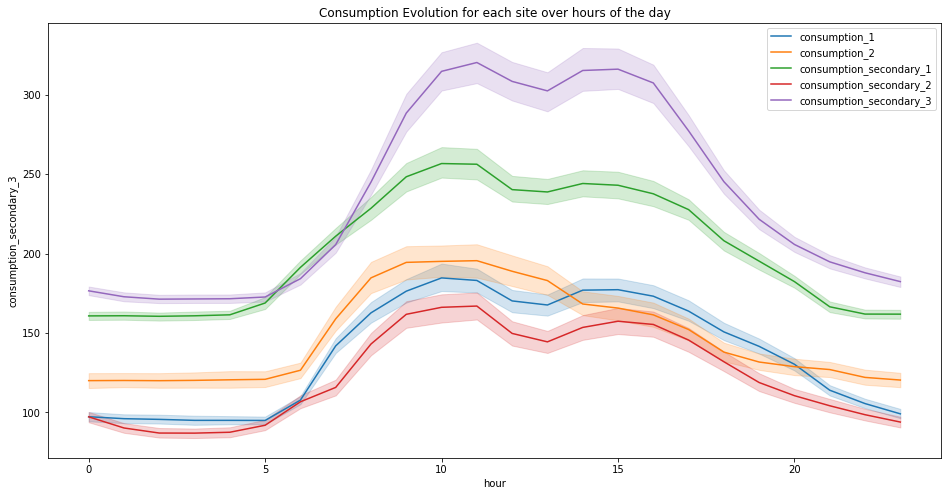
The graph above clearly shows that the electricity consumption is higher during working hours of the day.
plt.figure(figsize=(16, 8))
plt.title("Consumption Evolution for each site over weekday")
for c in ['consumption_1', 'consumption_2', 'consumption_secondary_1', 'consumption_secondary_2', 'consumption_secondary_3']:
sns.lineplot(x="day", y=c, data=df_viz, label=c)
plt.show()
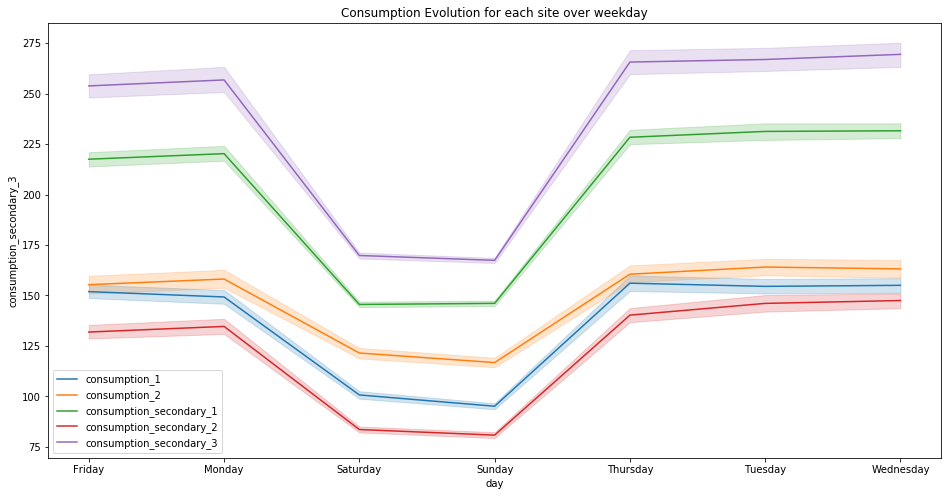
The consumption is lower during the week-end. So we can deduce that those sites are not housings.
plt.figure(figsize=(16, 8))
plt.title("Consumption Evolution for each site over a year")
for c in ['consumption_1', 'consumption_2', 'consumption_secondary_1', 'consumption_secondary_2', 'consumption_secondary_3']:
sns.lineplot(x="day of year", y=c, data=df_viz, label=c)
plt.show()
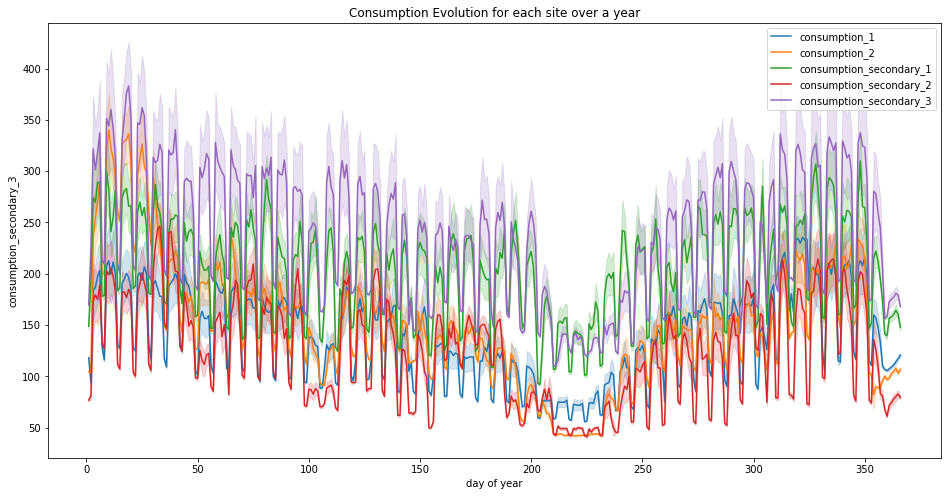
We can see that globally the mean consumption decreases until the summer, then increases until the end of the year.
plt.figure(figsize=(16, 8))
plt.title("Consumption Evolution for each site over a year during WORKING DAYS")
for c in ['consumption_1', 'consumption_2', 'consumption_secondary_1', 'consumption_secondary_2', 'consumption_secondary_3']:
sns.lineplot(x="day of year", y=c, data=df_viz[~df_viz['day'].isin(['Saturday', 'Sunday'])], label=c)
plt.show()
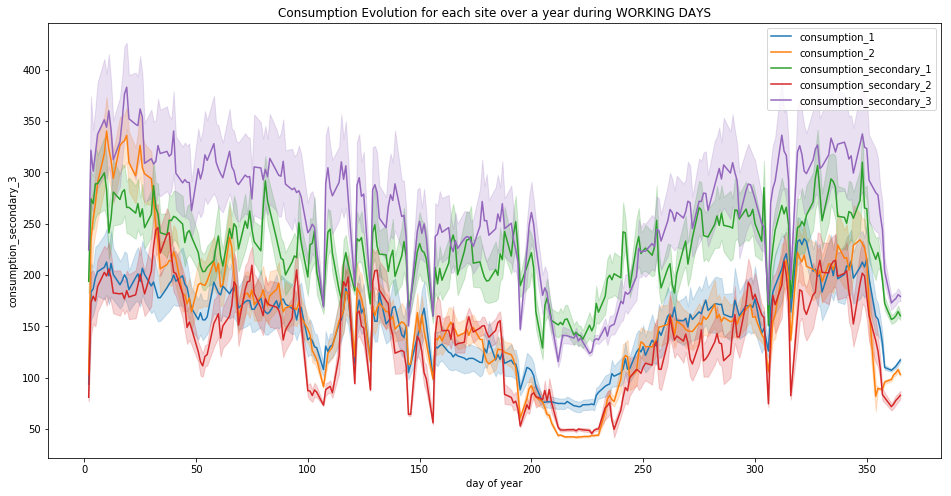
plt.figure(figsize=(16, 8))
plt.title("Mean Consumption Evolution for each site over months")
for c in ['consumption_1', 'consumption_2', 'consumption_secondary_1', 'consumption_secondary_2', 'consumption_secondary_3']:
sns.lineplot(data=df_viz.groupby(['month'])[c].mean(), label=c)
plt.show()
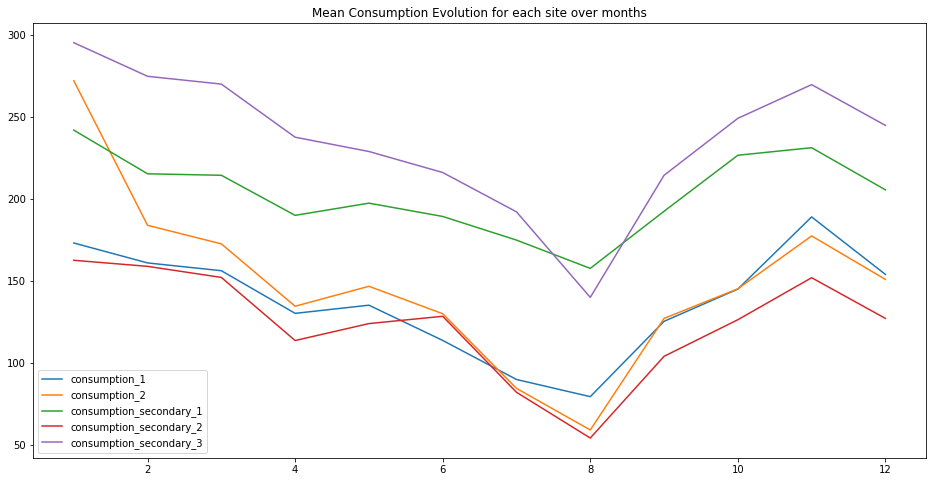
plt.figure(figsize=(16, 8))
plt.title("Mean Consumption Evolution for each site over weeks")
for c in ['consumption_1', 'consumption_2', 'consumption_secondary_1', 'consumption_secondary_2', 'consumption_secondary_3']:
sns.lineplot(data=df_viz.groupby(['week of year'])[c].mean(), label=c)
plt.show()
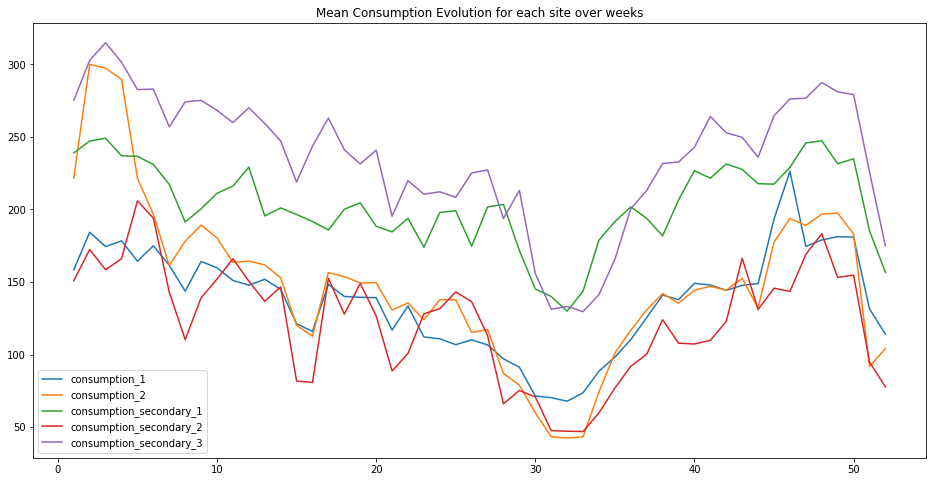
temp_consumption_cols = ['consumption_1', 'consumption_2', 'temp_1', 'temp_2']
df_viz[temp_consumption_cols] = MinMaxScaler().fit_transform(df_viz[temp_consumption_cols])
plt.figure(figsize=(16, 8))
plt.title("Correlation between Mean Consumption & Mean Temperatures / for each site over months")
for c in temp_consumption_cols:
sns.lineplot(data=df_viz.groupby(['month'])[c].mean(), label=c)
plt.show()
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/preprocessing/data.py:334: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by MinMaxScaler.
return self.partial_fit(X, y)
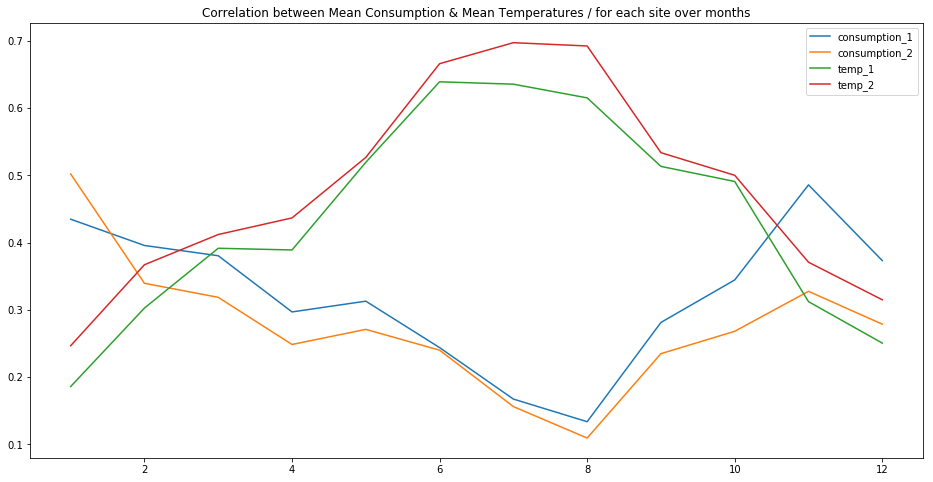
Electricity consumption and temperatures seem to be negatively correlated.
Features Engineering
Special dates - non working days “Jours fériés”
(credits: Antoine Augusti https://github.com/AntoineAugusti/jours-feries-france)
jf = pd.read_csv(os.path.join(input_dir, 'jours_feries_seuls.csv')).drop(columns=['nom_jour_ferie'])
# the date column is kept as a string for merging purposes
jf['est_jour_ferie'] = jf['est_jour_ferie'].astype('int')
jf.tail()
| date | est_jour_ferie | |
|---|---|---|
| 1102 | 2050-07-14 | 1 |
| 1103 | 2050-08-15 | 1 |
| 1104 | 2050-11-01 | 1 |
| 1105 | 2050-11-11 | 1 |
| 1106 | 2050-12-25 | 1 |
jf.est_jour_ferie.unique()
array([1])
Holidays
(credits: Antoine Augusti https://www.data.gouv.fr/fr/datasets/vacances-scolaires-par-zones/)
holidays = pd.read_csv(os.path.join(input_dir, 'vacances-scolaires.csv')).drop(columns=['nom_vacances'])
# the date column is kept as a string for merging purposes
for col in ['vacances_zone_a', 'vacances_zone_b', 'vacances_zone_c']:
holidays[col] = holidays[col].astype('int')
holidays.tail()
| date | vacances_zone_a | vacances_zone_b | vacances_zone_c | |
|---|---|---|---|---|
| 11318 | 2020-12-27 | 0 | 0 | 0 |
| 11319 | 2020-12-28 | 0 | 0 | 0 |
| 11320 | 2020-12-29 | 0 | 0 | 0 |
| 11321 | 2020-12-30 | 0 | 0 | 0 |
| 11322 | 2020-12-31 | 0 | 0 | 0 |
Sunlight hours
work in progress, more to come in the next days…stay tuned :)
Merging all infos
def merge_infos(data_frame):
data_frame = pd.merge(data_frame, holidays, on='date', how='left')
data_frame = pd.merge(data_frame, jf, on='date', how='left')
return data_frame
df = merge_infos(df)
df.vacances_zone_a.value_counts()/24
0 243.958333
1 121.041667
Name: vacances_zone_a, dtype: float64
df.est_jour_ferie.value_counts()/24
1.0 11.0
Name: est_jour_ferie, dtype: float64
Cleaning Data
def cleaning_data(data_frame):
# The Nan values of the column "est_jour_ferie" correspond to working days
# because in the dataset merged with, there is only non working days
data_frame['est_jour_ferie'] = data_frame['est_jour_ferie'].fillna(0)
# At first, missing values in the temperatures and humidity columns are replaced by the median ones
# later another approach with open data of means of the corresponding months will be used
for c in ['temp_1', 'temp_2', 'humidity_1', 'humidity_2']:
data_frame[c] = data_frame[c].fillna(data_frame[c].median())
return data_frame
df = cleaning_data(df)
df.isnull().sum()
timestamp 0
temp_1 0
temp_2 0
mean_national_temp 0
humidity_1 0
humidity_2 0
loc_1 0
loc_2 0
loc_secondary_1 0
loc_secondary_2 0
loc_secondary_3 0
consumption_secondary_1 0
consumption_secondary_2 0
consumption_secondary_3 0
datetime 0
month 0
week of year 0
day of year 0
day 0
hour 0
date 0
vacances_zone_a 0
vacances_zone_b 0
vacances_zone_c 0
est_jour_ferie 0
dtype: int64
df.head()
| timestamp | temp_1 | temp_2 | mean_national_temp | humidity_1 | humidity_2 | loc_1 | loc_2 | loc_secondary_1 | loc_secondary_2 | loc_secondary_3 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | datetime | month | week of year | day of year | day | hour | date | vacances_zone_a | vacances_zone_b | vacances_zone_c | est_jour_ferie | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016-11-01T00:00:00.0 | 8.3 | 14.5 | 11.1 | 95.0 | 65.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 143 | 74 | 168 | 2016-11-01 00:00:00 | 11 | 44 | 306 | Tuesday | 0 | 2016-11-01 | 1 | 1 | 1 | 1.0 |
| 1 | 2016-11-01T01:00:00.0 | 8.0 | 14.5 | 11.1 | 98.0 | 65.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 141 | 60 | 162 | 2016-11-01 01:00:00 | 11 | 44 | 306 | Tuesday | 1 | 2016-11-01 | 1 | 1 | 1 | 1.0 |
| 2 | 2016-11-01T02:00:00.0 | 6.8 | 14.5 | 11.0 | 97.0 | 65.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 142 | 60 | 164 | 2016-11-01 02:00:00 | 11 | 44 | 306 | Tuesday | 2 | 2016-11-01 | 1 | 1 | 1 | 1.0 |
| 3 | 2016-11-01T03:00:00.0 | 7.5 | 14.5 | 10.9 | 99.0 | 65.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 139 | 60 | 162 | 2016-11-01 03:00:00 | 11 | 44 | 306 | Tuesday | 3 | 2016-11-01 | 1 | 1 | 1 | 1.0 |
| 4 | 2016-11-01T04:00:00.0 | 6.1 | 14.5 | 10.8 | 98.0 | 65.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 154 | 60 | 164 | 2016-11-01 04:00:00 | 11 | 44 | 306 | Tuesday | 4 | 2016-11-01 | 1 | 1 | 1 | 1.0 |
Correlations
# after dummies
# sns.pairplot(df_viz.select_dtypes(['int64', 'float64']))#.apply(pd.Series.nunique, axis=0)
df_viz = pd.concat((df, df_out), axis=1)
corr = df_viz.corr()
# makes all correlations positive for the heatmap
corr = np.sqrt(corr * corr)
# Generate a mask for the upper triangle
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
plt.title('Correlations - beware all are made positive, in reality some are negative ones')
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5}, annot=True)
<matplotlib.axes._subplots.AxesSubplot at 0x7fce98470f28>
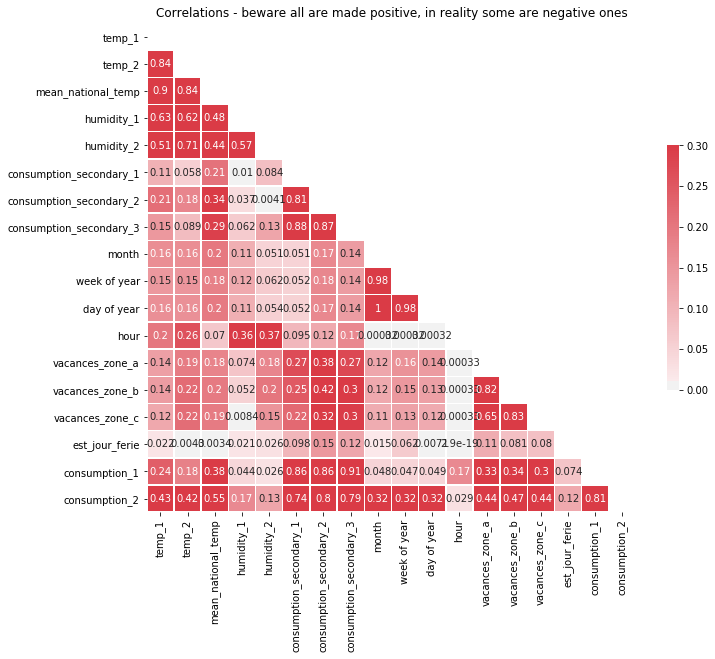
There medium correlations between weather informations. The given sites have also positively correlated consumption, this makes sense because all sites are housings. The targets seem to be weakly correlated with time infos…
Comparison between X_train & X_test
X_test = pd.read_csv(os.path.join(input_dir, 'input_test_cdKcI0e.csv'), index_col='ID')
X_test.iloc[23:26]
| timestamp | temp_1 | temp_2 | mean_national_temp | humidity_1 | humidity_2 | loc_1 | loc_2 | loc_secondary_1 | loc_secondary_2 | loc_secondary_3 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | ||||||||||||||
| 8783 | 2017-11-01T23:00:00.0 | 9.0 | 9.0 | 9.4 | 78.0 | 95.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 172 | 131 | 170 |
| 8784 | 2017-11-02T00:00:00.0 | 8.8 | 8.6 | 9.4 | 79.0 | 95.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 172 | 136 | 172 |
| 8785 | 2017-11-02T01:00:00.0 | 7.6 | 8.8 | 9.4 | 82.0 | 96.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 174 | 126 | 171 |
df.shape, X_test.shape
((8760, 25), (8736, 14))
There are 24 lines (hours) more wich correspond to one day, because 2016 was a leap year
X_test.iloc[[0, -1]]
| timestamp | temp_1 | temp_2 | mean_national_temp | humidity_1 | humidity_2 | loc_1 | loc_2 | loc_secondary_1 | loc_secondary_2 | loc_secondary_3 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | ||||||||||||||
| 8760 | 2017-11-01T00:00:00.0 | 6.5 | 7.1 | 8.8 | 91.0 | 82.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 190 | 126 | 177 |
| 17495 | 2018-10-30T23:00:00.0 | 7.5 | 11.2 | 6.7 | 85.0 | 77.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 228 | 114 | 178 |
df.iloc[[0, -1]]
| timestamp | temp_1 | temp_2 | mean_national_temp | humidity_1 | humidity_2 | loc_1 | loc_2 | loc_secondary_1 | loc_secondary_2 | loc_secondary_3 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | datetime | month | week of year | day of year | day | hour | date | vacances_zone_a | vacances_zone_b | vacances_zone_c | est_jour_ferie | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016-11-01T00:00:00.0 | 8.3 | 14.5 | 11.1 | 95.0 | 65.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 143 | 74 | 168 | 2016-11-01 00:00:00 | 11 | 44 | 306 | Tuesday | 0 | 2016-11-01 | 1 | 1 | 1 | 1.0 |
| 8759 | 2017-10-31T23:00:00.0 | 7.0 | 7.9 | 8.8 | 90.0 | 78.0 | (50.633, 3.067) | (43.530, 5.447) | (44.838, -0.579) | (47.478, -0.563) | (48.867, 2.333) | 198 | 128 | 189 | 2017-10-31 23:00:00 | 10 | 44 | 304 | Tuesday | 23 | 2017-10-31 | 1 | 1 | 1 | 0.0 |
There is a difference in the length of the two dataframes X_train & X_test
Data preparation
feat_to_drop = [
'timestamp',
'loc_1',
'loc_2',
'loc_secondary_1',
'loc_secondary_2',
'loc_secondary_3',
'datetime',
'date']
feat_to_scale = [
'temp_1',
'temp_2',
'mean_national_temp',
'humidity_1',
'humidity_2',
'consumption_secondary_1',
'consumption_secondary_2',
'consumption_secondary_3']
feat_to_dummies = [
'day',
'month',
'week of year',
#'day of year',
'hour']
Side note : let’s try to run models without dummification of day of year
def prepare_feat_df(data_frame):
data_frame = data_frame.drop(columns=feat_to_drop)
data_frame[feat_to_scale] = MinMaxScaler().fit_transform(data_frame[feat_to_scale])
data_frame = pd.get_dummies(data=data_frame, columns=feat_to_dummies, drop_first=True)
return data_frame
df = prepare_feat_df(df)
df.head(2)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/preprocessing/data.py:334: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by MinMaxScaler.
return self.partial_fit(X, y)
| temp_1 | temp_2 | mean_national_temp | humidity_1 | humidity_2 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | day of year | vacances_zone_a | vacances_zone_b | vacances_zone_c | est_jour_ferie | day_Monday | day_Saturday | day_Sunday | day_Thursday | day_Tuesday | day_Wednesday | month_2 | month_3 | month_4 | month_5 | month_6 | month_7 | month_8 | month_9 | month_10 | month_11 | month_12 | week of year_2 | week of year_3 | week of year_4 | week of year_5 | week of year_6 | week of year_7 | week of year_8 | week of year_9 | week of year_10 | week of year_11 | week of year_12 | week of year_13 | week of year_14 | week of year_15 | week of year_16 | week of year_17 | week of year_18 | week of year_19 | week of year_20 | week of year_21 | ... | week of year_26 | week of year_27 | week of year_28 | week of year_29 | week of year_30 | week of year_31 | week of year_32 | week of year_33 | week of year_34 | week of year_35 | week of year_36 | week of year_37 | week of year_38 | week of year_39 | week of year_40 | week of year_41 | week of year_42 | week of year_43 | week of year_44 | week of year_45 | week of year_46 | week of year_47 | week of year_48 | week of year_49 | week of year_50 | week of year_51 | week of year_52 | hour_1 | hour_2 | hour_3 | hour_4 | hour_5 | hour_6 | hour_7 | hour_8 | hour_9 | hour_10 | hour_11 | hour_12 | hour_13 | hour_14 | hour_15 | hour_16 | hour_17 | hour_18 | hour_19 | hour_20 | hour_21 | hour_22 | hour_23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.356234 | 0.466667 | 0.428571 | 0.936709 | 0.609195 | 0.155263 | 0.208451 | 0.155462 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0.348601 | 0.466667 | 0.428571 | 0.974684 | 0.609195 | 0.150000 | 0.169014 | 0.142857 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
2 rows × 104 columns
Data Preparation
def prepare_data(input_file_name, output_file_name1, output_file_name2):
data_frame = pd.read_csv(os.path.join(input_dir, input_file_name), index_col='ID')
data_frame = transform_datetime_infos(data_frame)
data_frame = merge_infos(data_frame)
data_frame = cleaning_data(data_frame)
data_frame = prepare_feat_df(data_frame)
df_1 = data_frame.drop(columns=['temp_2', 'humidity_2'])
df_2 = data_frame.drop(columns=['temp_1', 'humidity_1'])
df_1.to_csv(os.path.join(output_dir, output_file_name1), index=False)
df_2.to_csv(os.path.join(output_dir, output_file_name2), index=False)
#return df_1, df_2
prepare_data('input_training_ssnsrY0.csv', 'X_train_1.csv', 'X_train_2.csv')
prepare_data('input_test_cdKcI0e.csv', 'X_test_1.csv', 'X_test_2.csv')
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/preprocessing/data.py:334: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by MinMaxScaler.
return self.partial_fit(X, y)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/preprocessing/data.py:334: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by MinMaxScaler.
return self.partial_fit(X, y)
pd.read_csv(os.path.join(output_dir, 'X_train_1.csv')).head()
| temp_1 | mean_national_temp | humidity_1 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | day of year | vacances_zone_a | vacances_zone_b | vacances_zone_c | est_jour_ferie | day_Monday | day_Saturday | day_Sunday | day_Thursday | day_Tuesday | day_Wednesday | month_2 | month_3 | month_4 | month_5 | month_6 | month_7 | month_8 | month_9 | month_10 | month_11 | month_12 | week of year_2 | week of year_3 | week of year_4 | week of year_5 | week of year_6 | week of year_7 | week of year_8 | week of year_9 | week of year_10 | week of year_11 | week of year_12 | week of year_13 | week of year_14 | week of year_15 | week of year_16 | week of year_17 | week of year_18 | week of year_19 | week of year_20 | week of year_21 | week of year_22 | week of year_23 | ... | week of year_26 | week of year_27 | week of year_28 | week of year_29 | week of year_30 | week of year_31 | week of year_32 | week of year_33 | week of year_34 | week of year_35 | week of year_36 | week of year_37 | week of year_38 | week of year_39 | week of year_40 | week of year_41 | week of year_42 | week of year_43 | week of year_44 | week of year_45 | week of year_46 | week of year_47 | week of year_48 | week of year_49 | week of year_50 | week of year_51 | week of year_52 | hour_1 | hour_2 | hour_3 | hour_4 | hour_5 | hour_6 | hour_7 | hour_8 | hour_9 | hour_10 | hour_11 | hour_12 | hour_13 | hour_14 | hour_15 | hour_16 | hour_17 | hour_18 | hour_19 | hour_20 | hour_21 | hour_22 | hour_23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.356234 | 0.428571 | 0.936709 | 0.155263 | 0.208451 | 0.155462 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0.348601 | 0.428571 | 0.974684 | 0.150000 | 0.169014 | 0.142857 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.318066 | 0.425249 | 0.962025 | 0.152632 | 0.169014 | 0.147059 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0.335878 | 0.421927 | 0.987342 | 0.144737 | 0.169014 | 0.142857 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0.300254 | 0.418605 | 0.974684 | 0.184211 | 0.169014 | 0.147059 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 102 columns
df_out['consumption_1'].to_csv(os.path.join('..', 'output', 'y_train_1.csv'), index=False)
df_out['consumption_2'].to_csv(os.path.join('..', 'output', 'y_train_2.csv'), index=False)
Conclusion
In this first part, we’ve made an exploration of the data, thus you can see :
- how the weather (and particularly the temperature) could influence the electricity consumption. And the other correlations.
- how cyclic time infos are, and how the consumption vary depending on the hour of the day, the day of the week and the week of the year Then we’ve have cleaned and prepared the datasets that will be used in the following part by the machine learning models.
Predictions with various types of ML models
In this second part i’ll use machine learning models to make predictions and submission to see my score for this challenge.
- At first i’ll use linear regressorts, then the SVM model with 2 different kernels.
- Then, later i’ll see if random forrest and gradient boosting libs are more effective
- At the end, i’ll try to use deep learning models such as RNN and especially GRU.
Data preparation
Some parts of the data set have aldready been prepared in the first notebook / blogpost, and saved as different csv file. Anyway i’ll reuse the same function in order to prepare the data for the deep learning models (see below).
First let’s import all the libraries needed, set up notebook parameter, create file / folder paths and load the data :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
pd.set_option('display.max_columns', 100)
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Lasso, ElasticNet, ridge_regression, LinearRegression, Ridge
from sklearn.svm import SVR
input_dir = os.path.join('..', 'input')
output_dir = os.path.join('..', 'output')
# each id is unique so we can use this column as index
X_train_1 = pd.read_csv(os.path.join(output_dir, "X_train_1.csv"))
X_train_2 = pd.read_csv(os.path.join(output_dir, "X_train_2.csv"))
X_test_1 = pd.read_csv(os.path.join(output_dir, "X_test_1.csv"))
X_test_2 = pd.read_csv(os.path.join(output_dir, "X_test_2.csv"))
X_train_1.head()
| temp_1 | mean_national_temp | humidity_1 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | day of year | vacances_zone_a | vacances_zone_b | vacances_zone_c | est_jour_ferie | day_Monday | day_Saturday | day_Sunday | day_Thursday | day_Tuesday | day_Wednesday | month_2 | month_3 | month_4 | month_5 | month_6 | month_7 | month_8 | month_9 | month_10 | month_11 | month_12 | week of year_2 | week of year_3 | week of year_4 | week of year_5 | week of year_6 | week of year_7 | week of year_8 | week of year_9 | week of year_10 | week of year_11 | week of year_12 | week of year_13 | week of year_14 | week of year_15 | week of year_16 | week of year_17 | week of year_18 | week of year_19 | week of year_20 | week of year_21 | week of year_22 | week of year_23 | ... | week of year_26 | week of year_27 | week of year_28 | week of year_29 | week of year_30 | week of year_31 | week of year_32 | week of year_33 | week of year_34 | week of year_35 | week of year_36 | week of year_37 | week of year_38 | week of year_39 | week of year_40 | week of year_41 | week of year_42 | week of year_43 | week of year_44 | week of year_45 | week of year_46 | week of year_47 | week of year_48 | week of year_49 | week of year_50 | week of year_51 | week of year_52 | hour_1 | hour_2 | hour_3 | hour_4 | hour_5 | hour_6 | hour_7 | hour_8 | hour_9 | hour_10 | hour_11 | hour_12 | hour_13 | hour_14 | hour_15 | hour_16 | hour_17 | hour_18 | hour_19 | hour_20 | hour_21 | hour_22 | hour_23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.356234 | 0.428571 | 0.936709 | 0.155263 | 0.208451 | 0.155462 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0.348601 | 0.428571 | 0.974684 | 0.150000 | 0.169014 | 0.142857 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.318066 | 0.425249 | 0.962025 | 0.152632 | 0.169014 | 0.147059 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0.335878 | 0.421927 | 0.987342 | 0.144737 | 0.169014 | 0.142857 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0.300254 | 0.418605 | 0.974684 | 0.184211 | 0.169014 | 0.147059 | 306 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 102 columns
X_test_1.head()
| temp_1 | mean_national_temp | humidity_1 | consumption_secondary_1 | consumption_secondary_2 | consumption_secondary_3 | day of year | vacances_zone_a | vacances_zone_b | vacances_zone_c | est_jour_ferie | day_Monday | day_Saturday | day_Sunday | day_Thursday | day_Tuesday | day_Wednesday | month_2 | month_3 | month_4 | month_5 | month_6 | month_7 | month_8 | month_9 | month_10 | month_11 | month_12 | week of year_2 | week of year_3 | week of year_4 | week of year_5 | week of year_6 | week of year_7 | week of year_8 | week of year_9 | week of year_10 | week of year_11 | week of year_12 | week of year_13 | week of year_14 | week of year_15 | week of year_16 | week of year_17 | week of year_18 | week of year_19 | week of year_20 | week of year_21 | week of year_22 | week of year_23 | ... | week of year_26 | week of year_27 | week of year_28 | week of year_29 | week of year_30 | week of year_31 | week of year_32 | week of year_33 | week of year_34 | week of year_35 | week of year_36 | week of year_37 | week of year_38 | week of year_39 | week of year_40 | week of year_41 | week of year_42 | week of year_43 | week of year_44 | week of year_45 | week of year_46 | week of year_47 | week of year_48 | week of year_49 | week of year_50 | week of year_51 | week of year_52 | hour_1 | hour_2 | hour_3 | hour_4 | hour_5 | hour_6 | hour_7 | hour_8 | hour_9 | hour_10 | hour_11 | hour_12 | hour_13 | hour_14 | hour_15 | hour_16 | hour_17 | hour_18 | hour_19 | hour_20 | hour_21 | hour_22 | hour_23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.315315 | 0.368750 | 0.884615 | 0.202381 | 0.380665 | 0.189583 | 305 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0.322072 | 0.365625 | 0.858974 | 0.200000 | 0.350453 | 0.179167 | 305 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.322072 | 0.365625 | 0.846154 | 0.214286 | 0.353474 | 0.185417 | 305 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0.299550 | 0.362500 | 0.871795 | 0.219048 | 0.347432 | 0.177083 | 305 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0.281532 | 0.359375 | 0.871795 | 0.221429 | 0.347432 | 0.183333 | 305 | 1 | 1 | 1 | 1.0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 102 columns
Let’s verify the shape (nb of lines and columns) of the various data sets
X_train_1.shape, X_train_2.shape, X_test_1.shape, X_test_2.shape
((8760, 102), (8760, 102), (8736, 102), (8736, 102))
An overview of the test data set use to make submissions for the challenge :
y_train_1 = pd.read_csv("../output/y_train_1.csv", header=None)
y_train_2 = pd.read_csv("../output/y_train_2.csv", header=None)
y_train_1.head()
| 0 | |
|---|---|
| 0 | 100 |
| 1 | 101 |
| 2 | 100 |
| 3 | 101 |
| 4 | 100 |
y_train_1.shape, y_train_2.shape
((8760, 1), (8760, 1))
Metric / Benchmark
For this challenge we used the mean absolute error.
Even though the RMSE is generally the preferred performance measure for regression tasks, in some contexts you may prefer to use another function. For example, suppose that there are many outlier dstricts. In that case, you may consider using the Mean Absolute Error.
Both the RMSE and the MAE are ways to measure the distance between two vectors: the vector of predictions and the vector of target values. Various distance measures, or norms, are possible:
-
Computing the root of a sum of squares (RMSE) corresponds to the Euclidian norm: it is the notion of distance you are familiar with. It is also called the l 2 norm, noted ∥ · ∥ 2 (or just ∥ · ∥).
-
Computing the sum of absolutes (MAE) corresponds to the l 1 norm, noted ∥ · ∥ 1 . It is sometimes called the Manhattan norm because it measures the distance between two points in a city if you can only travel along orthogonal city blocks.
The RMSE is more sensitive to outliers than the MAE. But when outliers are exponentially rare (like in a bell-shaped curve), the RMSE performs very well and is generally preferred.
def weighted_mean_absolute_error(y_true, y_pred):
""" Simplified version without loading csv for testing purposes on train sets"""
c12 = np.array([1136987, 1364719])
return 2 * mean_absolute_error(y_true*c12[0], y_pred*c12[1]) / np.sum(c12)
On the assumption that a safety reserve of 20% is needed to covert the supply
Functions to print/show predictions and make submissions
Please refer to the doc string of each function to know what’s its purpose, name should be self explanatory :
def print_metric_on_train(fitted_model_1, fitted_model_2):
""" prints and returns the metric on the train datasets"""
y_train_pred_1, y_train_pred_2 = fitted_model_1.predict(X_train_1), fitted_model_2.predict(X_train_2)
# arg = dataframe_1_y_true, dataframe_2_y_pred
wmae_1 = weighted_mean_absolute_error(y_train_1, y_train_pred_1)
wmae_2 = weighted_mean_absolute_error(y_train_2, y_train_pred_2)
print(f'weighted_mean_absolute_error on X_train_1 : {wmae_1}')
print(f'weighted_mean_absolute_error on X_train_2 : {wmae_2}')
return wmae_1, wmae_2, y_train_pred_1, y_train_pred_2
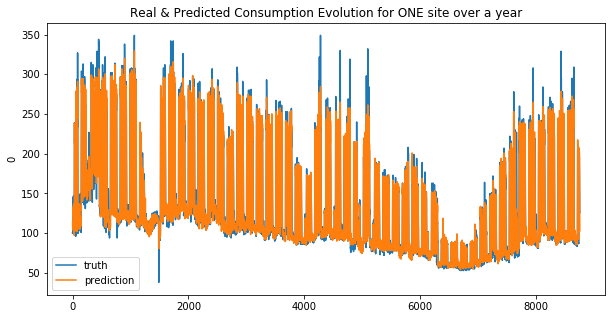
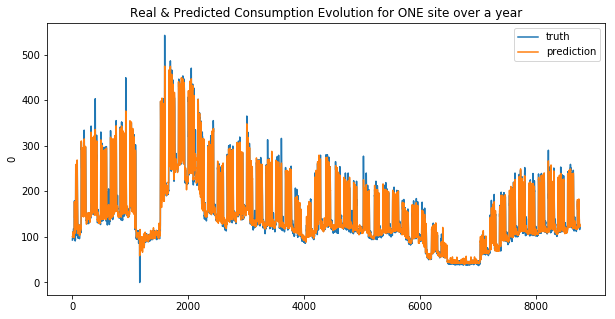
def display_pred_on_train(y_train, y_train_pred):
""" plots the prediction and the target of the ONE train data sets in order to see how the model has learnt"""
plt.figure(figsize=(10, 5))
plt.title("Real & Predicted Consumption Evolution for ONE site over a year")
sns.lineplot(x=y_train.index, y=y_train[0], label='truth')
#sns.lineplot(x=y_train.index, y=y_train_pred[:, 0], label='prediction')
sns.lineplot(x=y_train.index, y=y_train_pred, label='prediction')
plt.show()
def create_submission(fitted_model_1, fitted_model_2, model_name):
""" make the prediction on the test set and craft the specific csv file to be submitted"""
y_pred_1 = pd.DataFrame(fitted_model_1.predict(X_test_1).astype(int))
y_pred_2 = pd.DataFrame(fitted_model_2.predict(X_test_2).astype(int))
#y_pred_1, y_pred_2 = 1.2 * y_pred_1, 1.2 * y_pred_2 # no need of 20% more
res = pd.concat((y_pred_1, y_pred_2), axis=1)
res.columns = ['consumption_1', 'consumption_2']
res = res.set_index(pd.Index(range(8760, 17496)))
res.index.name = 'ID'
name = 'y_pred_' + model_name + '_.csv'
res.to_csv(os.path.join(output_dir, name), sep=',', index=True)
return y_pred_1, y_pred_2
def general_wrapper(fitted_model_1, fitted_model_2, model_name, y_train_1, y_train_2):
""" wrapper of the 3 functions above, so you only have to call this function instead"""
wmae_1, wmae_2, y_train_pred_1, y_train_pred_2 = print_metric_on_train(fitted_model_1, fitted_model_2)
display_pred_on_train(y_train_1, y_train_pred_1)
display_pred_on_train(y_train_2, y_train_pred_2)
create_submission(fitted_model_1, fitted_model_2, model_name)
return wmae_1, wmae_2
Side note
Remember that there is a difference in the length of the two dataframes X_train & X_test : there are 24 lines (hours) more wich correspond to one day, because 2016 was a leap year
Linear regression and Support Vector Machine
Here is a king of decision tree for choosing the right model :
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
- samples nb > 100k
- SGD regressor
- samples nb < 100k
- Few features should be important : YES:
- Lasso
- ElasticNet
- Few features should be important : NO:
- RidgeRegression
- SVR(kernel=’linear’) If not working
- SVR(kernel=’rbf’)
- Ensemble regressor
- Few features should be important : YES:
Linear reg
linear_base_1, linear_base_2 = LinearRegression(), LinearRegression()
linear_base_1.fit(X_train_1, y_train_1)
linear_base_2.fit(X_train_2, y_train_2)
res_lin_reg_1, res_lin_reg_2 = general_wrapper(linear_base_1, linear_base_2, 'linear_reg', y_train_1, y_train_2)
weighted_mean_absolute_error on X_train_1 : 26.05531062095511
weighted_mean_absolute_error on X_train_2 : 28.69959036370805
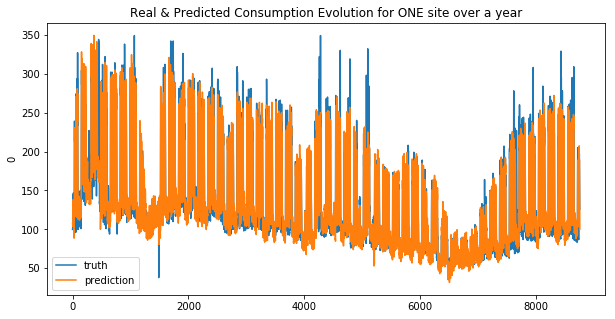
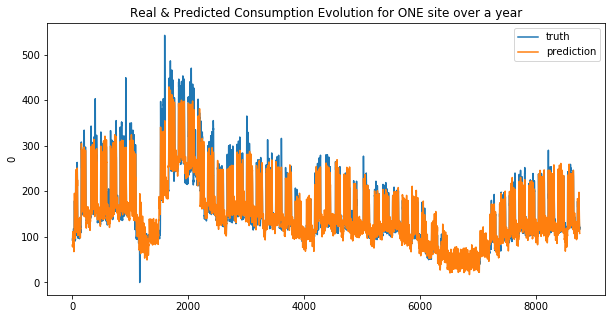
Your submission score is : 19.24
We can see that the linear regression model doesn’t make good predictions for spikes… this is more obvious for the second site. And that why the MAE was choosen !
Lasso
lasso_base_1, lasso_base_2 = Lasso(alpha=0.01, max_iter=10e5), Lasso(alpha=0.01, max_iter=10e5)
lasso_base_1.fit(X_train_1, y_train_1)
lasso_base_2.fit(X_train_2, y_train_2)
res_lasso_1, res_lasso_2 = general_wrapper(lasso_base_1, lasso_base_2, 'lasso', y_train_1, y_train_2)
weighted_mean_absolute_error on X_train_1 : 26.061965525312893
weighted_mean_absolute_error on X_train_2 : 28.710534100722768
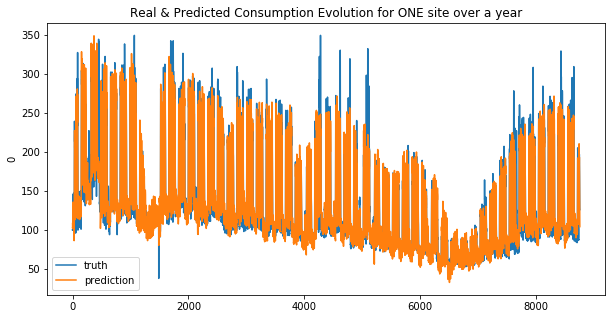
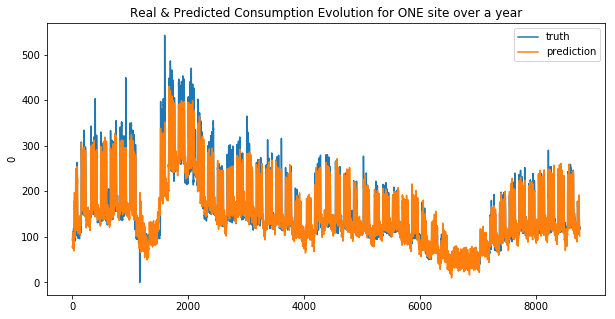
Your submission score is : 23.70
ElasticNet
elast_base_1, elast_base_2 = ElasticNet(alpha=0.01, max_iter=10e8), ElasticNet(alpha=0.1, max_iter=10e8)
elast_base_1.fit(X_train_1, y_train_1)
elast_base_2.fit(X_train_2, y_train_2)
res_elasticnet_1, res_elasticnet_2 = general_wrapper(elast_base_1, elast_base_2, 'elastic_net', y_train_1, y_train_2)
weighted_mean_absolute_error on X_train_1 : 26.16342615122434
weighted_mean_absolute_error on X_train_2 : 31.322618027652748
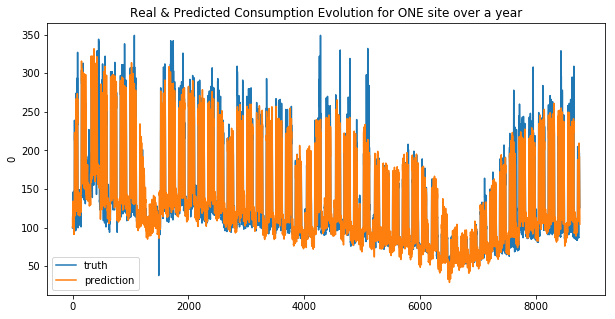
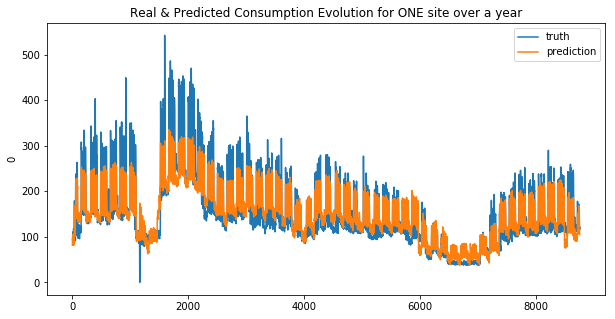
Your submission score is : 23.70
RidgeRegression
ridge_base_1, ridge_base_2 = Ridge(alpha=0.1, max_iter=10e10), Ridge(alpha=0.1, max_iter=10e10)
ridge_base_1.fit(X_train_1, y_train_1)
ridge_base_2.fit(X_train_2, y_train_2)
create_submission(ridge_base_1, ridge_base_2, 'ridge_reg')
res_ridge_1, res_ridge_2 = general_wrapper(ridge_base_1, ridge_base_2, 'ridge_reg', y_train_1, y_train_2)
weighted_mean_absolute_error on X_train_1 : 26.055361466167927
weighted_mean_absolute_error on X_train_2 : 28.695385473745706
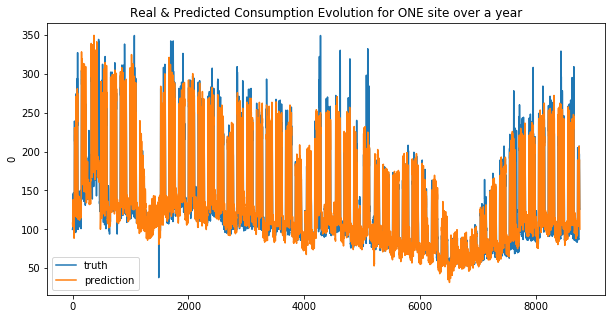
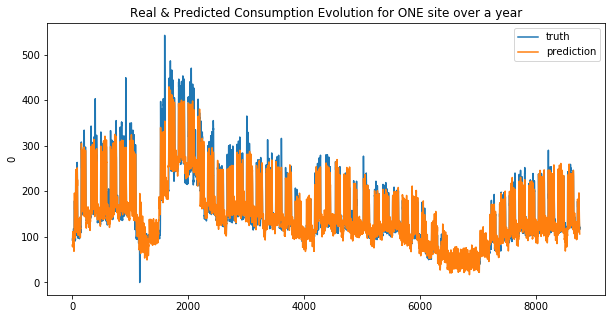
Your submission score is : 23.70
SVR(kernel=’linear’)
svr_base_1 = SVR(kernel='linear')
svr_base_2 = SVR(kernel='linear')
svr_base_1.fit(X_train_1, y_train_1)
svr_base_2.fit(X_train_2, y_train_2)
res_svr_1, res_svr_2 = general_wrapper(svr_base_1, svr_base_2, 'svr_lin', y_train_1, y_train_2)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
weighted_mean_absolute_error on X_train_1 : 24.78463504218071
weighted_mean_absolute_error on X_train_2 : 26.999353814493194
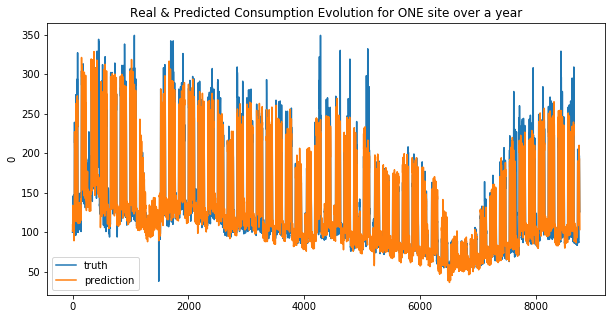
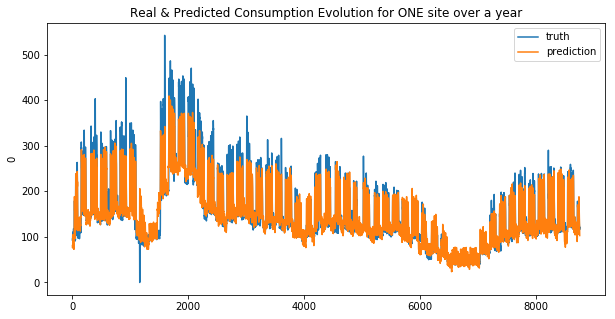
Your submission score is : 21.906794341911045
SVR(kernel=’rbf’)
#svr_base_1 = SVR(kernel='rbf', degree=3, gamma='auto_deprecated', coef0=0.0, tol=0.001, C=1.0, epsilon=0.1, shrinking=True, cache_size=200, verbose=False, max_iter=-1)
svr_base_rbf_1 = SVR(kernel='rbf')
svr_base_rbf_2 = SVR(kernel='rbf')
svr_base_rbf_1.fit(X_train_1, y_train_1)
svr_base_rbf_2.fit(X_train_2, y_train_2)
res_svr_base_rbf_1, res_svr_base_rbf_2 = general_wrapper(svr_base_rbf_1, svr_base_rbf_2, 'svr_base_rbf', y_train_1, y_train_2)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
weighted_mean_absolute_error on X_train_1 : 39.22806743679658
weighted_mean_absolute_error on X_train_2 : 33.98994529863917
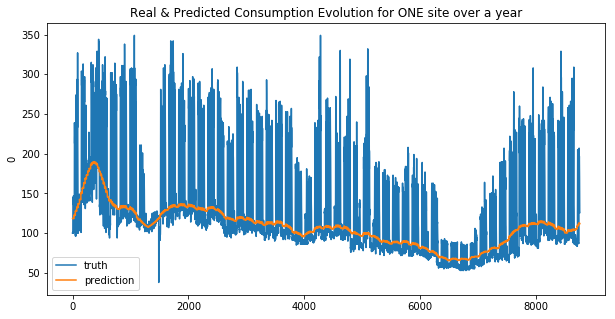
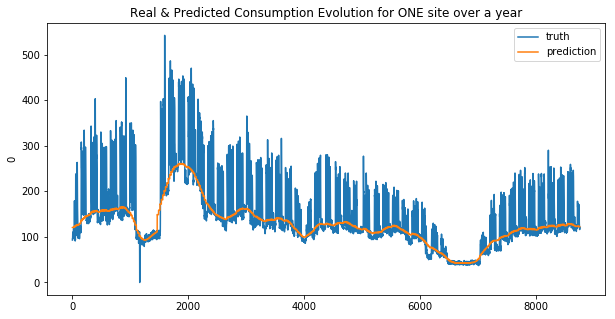
Your submission score is : 23.70
Using other models (random forrest type)
from sklearn.ensemble import AdaBoostRegressor, GradientBoostingRegressor, RandomForestRegressor, ExtraTreesRegressor
Adaboost Regressor
adaboost_base_1, adaboost_base_2 = AdaBoostRegressor(), AdaBoostRegressor()
adaboost_base_1.fit(X_train_1, y_train_1)
adaboost_base_2.fit(X_train_2, y_train_2)
res_adaboost_1, res_adaboost_2 = general_wrapper(adaboost_base_1, adaboost_base_2, 'adaboost_reg', y_train_1, y_train_2)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
weighted_mean_absolute_error on X_train_1 : 42.93679688417296
weighted_mean_absolute_error on X_train_2 : 46.10227435920769
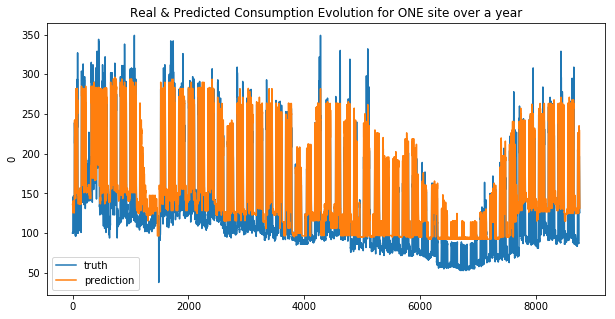
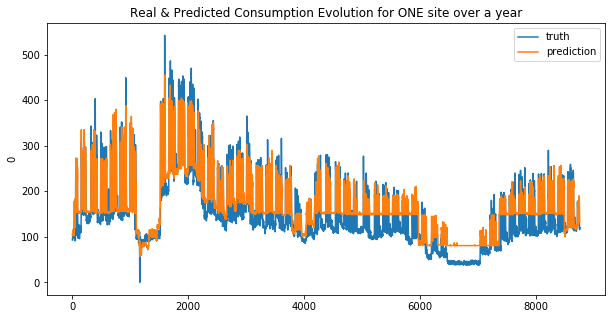
Your submission score is : 30.29205877610584
GradientBoosting Regressor
gbreg_base_1, gbreg_base_2 = GradientBoostingRegressor(), GradientBoostingRegressor()
gbreg_base_1.fit(X_train_1, y_train_1)
gbreg_base_2.fit(X_train_2, y_train_2)
res_gbreg_1, res_gbreg_2 = general_wrapper(gbreg_base_1, gbreg_base_2, 'gradientboost_reg', y_train_1, y_train_2)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
weighted_mean_absolute_error on X_train_1 : 25.6597272086074
weighted_mean_absolute_error on X_train_2 : 27.55942042756231
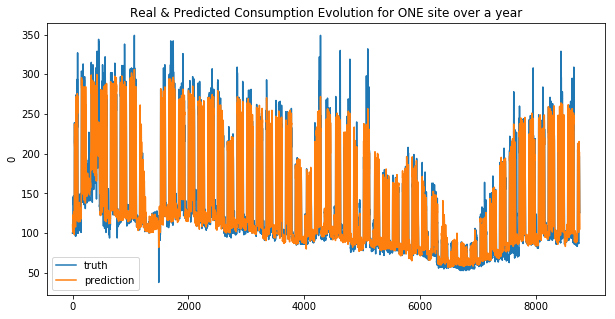
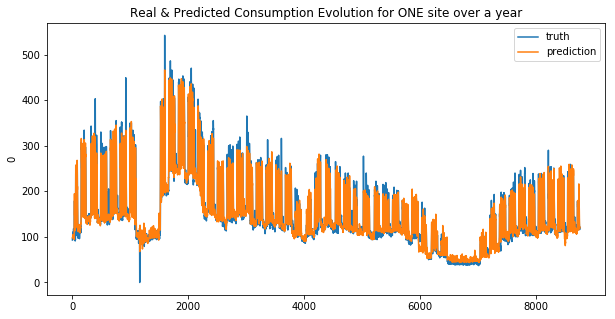
Your submission score is : ??????
RandomForestRegressor
rfreg_base_1, rfreg_base_2 = RandomForestRegressor(), RandomForestRegressor()
rfreg_base_1.fit(X_train_1, y_train_1)
rfreg_base_2.fit(X_train_2, y_train_2)
res_rfreg_1, res_rfreg_2 = general_wrapper(rfreg_base_1, rfreg_base_2, 'randomforrest_reg', y_train_1, y_train_2)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/ipykernel_launcher.py:2: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
/home/sunflowa/Anaconda/lib/python3.7/site-packages/ipykernel_launcher.py:3: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
This is separate from the ipykernel package so we can avoid doing imports until
weighted_mean_absolute_error on X_train_1 : 25.072702321232793
weighted_mean_absolute_error on X_train_2 : 27.064664489582444
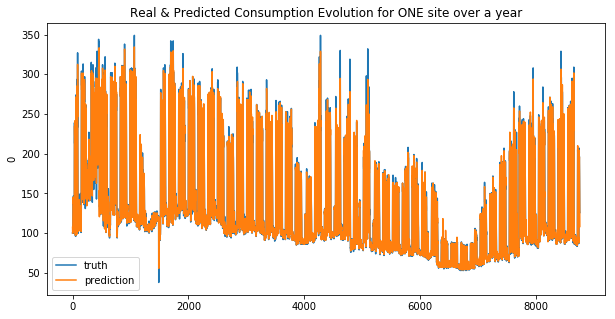
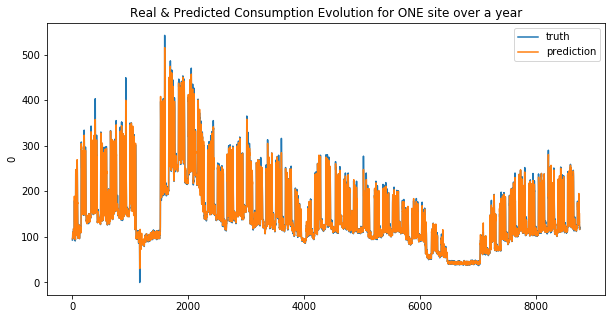
Your submission score is : ??????
ExtraTreesRegressor
etreg_base_1, etreg_base_2 = ExtraTreesRegressor(), ExtraTreesRegressor()
etreg_base_1.fit(X_train_1, y_train_1)
etreg_base_2.fit(X_train_2, y_train_2)
res_etreg_1, res_etreg_2 = general_wrapper(etreg_base_1, etreg_base_2, 'extratree_reg', y_train_1, y_train_2)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/ipykernel_launcher.py:2: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
/home/sunflowa/Anaconda/lib/python3.7/site-packages/ipykernel_launcher.py:3: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
This is separate from the ipykernel package so we can avoid doing imports until
weighted_mean_absolute_error on X_train_1 : 25.042457117491335
weighted_mean_absolute_error on X_train_2 : 27.041557371295493
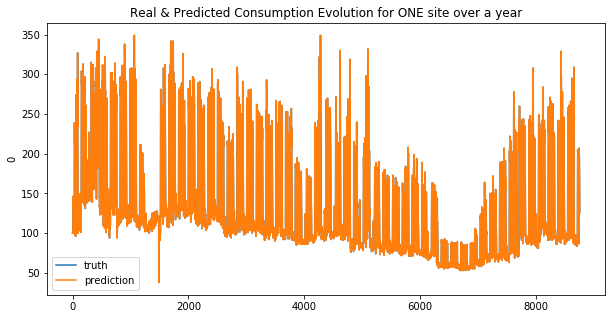
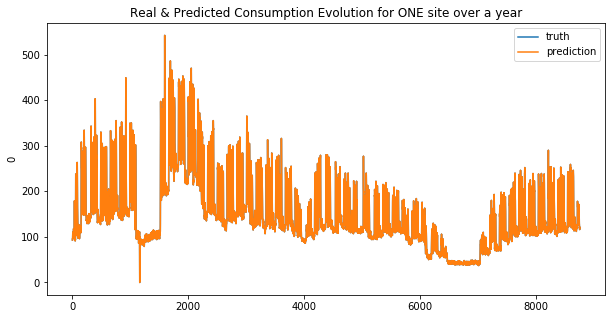
Your submission score is : ??????
import other libraries
import xgboost as xgb
import lightgbm as lgbm
XGBoost Regressor
XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. The same code runs on major distributed environment (Hadoop, SGE, MPI) and can solve problems beyond billions of examples.
https://xgboost.readthedocs.io/en/latest/
xgbreg_base_1, xgbreg_base_2 = xgb.XGBRegressor(), xgb.XGBRegressor()
xgbreg_base_1.fit(X_train_1, y_train_1)
xgbreg_base_2.fit(X_train_2, y_train_2)
res_xgbreg_1, res_xgbreg_2 = general_wrapper(xgbreg_base_1, xgbreg_base_2, 'xgb_reg', y_train_1, y_train_2)
weighted_mean_absolute_error on X_train_1 : 25.670042893699705
weighted_mean_absolute_error on X_train_2 : 27.57397787858485
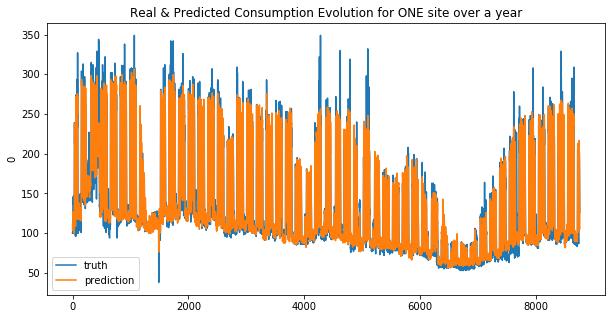
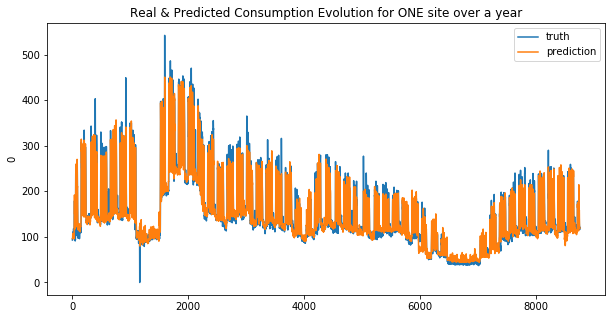
Your submission score is : ??????
Light GBM Regressor
LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed and efficient with the following advantages: https://lightgbm.readthedocs.io/en/latest/
- Faster training speed and higher efficiency.
- Lower memory usage.
- Better accuracy.
- Support of parallel and GPU learning.
- Capable of handling large-scale data.
For more details, please refer to Features.
lgbmreg_base_1, lgbmreg_base_2 = lgbm.LGBMRegressor(), lgbm.LGBMRegressor()
lgbmreg_base_1.fit(X_train_1, y_train_1)
lgbmreg_base_2.fit(X_train_2, y_train_2)
res_lgbmreg_1, res_lgbmreg_2 = general_wrapper(lgbmreg_base_1, lgbmreg_base_2, 'lgbm_reg', y_train_1, y_train_2)
weighted_mean_absolute_error on X_train_1 : 25.169500507539915
weighted_mean_absolute_error on X_train_2 : 27.088282579499793
Your submission score is : ??????
Using Recurrent Neural Networks
let’s import all the needed libs from tensorflow / keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense, GRU
A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes form a directed graph along a temporal sequence. This allows it to exhibit temporal dynamic behavior. Unlike feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition.
The term “recurrent neural network” is used indiscriminately to refer to two broad classes of networks with a similar general structure, where one is finite impulse and the other is infinite impulse. Both classes of networks exhibit temporal dynamic behavior. A finite impulse recurrent network is a directed acyclic graph that can be unrolled and replaced with a strictly feedforward neural network, while an infinite impulse recurrent network is a directed cyclic graph that can not be unrolled.
Both finite impulse and infinite impulse recurrent networks can have additional stored state, and the storage can be under direct control by the neural network. The storage can also be replaced by another network or graph, if that incorporates time delays or has feedback loops. Such controlled states are referred to as gated state or gated memory, and are part of long short-term memory networks (LSTMs) and gated recurrent units.This is also called Feedback Neural Network.
https://en.wikipedia.org/wiki/Recurrent_neural_network
Data preparation
same as before in the 1st part : see intro & EDA
def transform_datetime_infos(data_frame):
data_frame['datetime'] = pd.to_datetime(data_frame['timestamp'])
data_frame['month'] = data_frame['datetime'].dt.month
data_frame['week of year'] = data_frame['datetime'].dt.weekofyear
data_frame['day of year'] = data_frame['datetime'].dt.dayofyear
data_frame['day'] = data_frame['datetime'].dt.weekday_name
data_frame['hour'] = data_frame['datetime'].dt.hour
# for merging purposes
data_frame['date'] = data_frame['datetime'].dt.strftime('%Y-%m-%d')
return data_frame
def merge_infos(data_frame):
data_frame = pd.merge(data_frame, holidays, on='date', how='left')
data_frame = pd.merge(data_frame, jf, on='date', how='left')
return data_frame
def cleaning_data(data_frame):
# The Nan values of the column "est_jour_ferie" correspond to working days
# because in the dataset merged with, there is only non working days
data_frame['est_jour_ferie'] = data_frame['est_jour_ferie'].fillna(0)
# At first, missing values in the temperatures and humidity columns are replaced by the median ones
# later another approach with open data of means of the corresponding months will be used
for c in ['temp_1', 'temp_2', 'humidity_1', 'humidity_2']:
data_frame[c] = data_frame[c].fillna(data_frame[c].median())
return data_frame
feat_to_drop = [
'timestamp',
'loc_1',
'loc_2',
'loc_secondary_1',
'loc_secondary_2',
'loc_secondary_3',
'datetime',
'date']
feat_to_scale = [
'temp_1',
'temp_2',
'mean_national_temp',
'humidity_1',
'humidity_2',
'consumption_secondary_1',
'consumption_secondary_2',
'consumption_secondary_3']
feat_to_dummies = [
'day',
'month',
'week of year',
#'day of year',
'hour']
def prepare_feat_df(data_frame):
data_frame = data_frame.drop(columns=feat_to_drop)
data_frame[feat_to_scale] = StandardScaler().fit_transform(data_frame[feat_to_scale])
data_frame = pd.get_dummies(data=data_frame, columns=feat_to_dummies, drop_first=True)
return data_frame
holidays = pd.read_csv(os.path.join(input_dir, 'vacances-scolaires.csv')).drop(columns=['nom_vacances'])
# the date column is kept as a string for merging purposes
for col in ['vacances_zone_a', 'vacances_zone_b', 'vacances_zone_c']:
holidays[col] = holidays[col].astype('int')
jf = pd.read_csv(os.path.join(input_dir, 'jours_feries_seuls.csv')).drop(columns=['nom_jour_ferie'])
# the date column is kept as a string for merging purposes
jf['est_jour_ferie'] = jf['est_jour_ferie'].astype('int')
input_dir = os.path.join('..', 'input')
output_dir = os.path.join('..', 'output')
X_train = pd.read_csv(os.path.join(input_dir, 'input_training_ssnsrY0.csv'), index_col='ID')
X_test = pd.read_csv(os.path.join(input_dir, 'input_test_cdKcI0e.csv'), index_col='ID')
y_train = pd.read_csv(os.path.join(input_dir, 'output_training_Uf11I9I.csv'), index_col='ID')
X_train, X_test = transform_datetime_infos(X_train), transform_datetime_infos(X_test)
X_train, X_test = merge_infos(X_train), merge_infos(X_test)
X_train, X_test = cleaning_data(X_train), cleaning_data(X_test)
X_train, X_test = prepare_feat_df(X_train), prepare_feat_df(X_test)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/preprocessing/data.py:645: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by StandardScaler.
return self.partial_fit(X, y)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/base.py:464: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by StandardScaler.
return self.fit(X, **fit_params).transform(X)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/preprocessing/data.py:645: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by StandardScaler.
return self.partial_fit(X, y)
/home/sunflowa/Anaconda/lib/python3.7/site-packages/sklearn/base.py:464: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by StandardScaler.
return self.fit(X, **fit_params).transform(X)
X_train.shape, X_test.shape, y_train.shape
((8760, 104), (8736, 104), (8760, 2))
Simple RNN
X_train_rnn = np.expand_dims(np.array(X_train.iloc[:48, :]), axis=0)
i = 49
while i < X_train.shape[0]:
X_temp = np.expand_dims(np.array(X_train.iloc[(i-48):i, :]), axis=0)
X_train_rnn = np.concatenate((X_train_rnn, X_temp), axis=0)
i += 1
y_train = y_train.iloc[48:]
X_train_rnn.shape, y_train.shape
((8712, 48, 104), (8712, 2))
shape = X_train_rnn.shape
shape
(8712, 48, 104)
X_train_rnn = X_train_rnn.reshape(shape[0], -1)
scaler = StandardScaler()
X_train_rnn = scaler.fit_transform(X_train_rnn)
X_train_rnn = X_train_rnn.reshape(shape[0], shape[1], shape[2])
X_train_rnn.shape
(8712, 48, 104)
X_test_init = X_train[-48:]
X_test_init.shape
X_test_temp = pd.concat([X_test_init, X_test])
X_test_temp.shape
(8784, 104)
X_test_rnn = np.expand_dims(np.array(X_test_temp.iloc[:48, :]), axis=0)
i = 49
while i < X_test_temp.shape[0]:
X_temp = np.expand_dims(np.array(X_test_temp.iloc[(i-48):i, :]), axis=0)
X_test_rnn = np.concatenate((X_test_rnn, X_temp), axis=0)
i += 1
X_test_rnn.shape
(8736, 48, 104)
shape = X_test_rnn.shape
shape
(8736, 48, 104)
X_test_rnn = X_test_rnn.reshape(shape[0], -1)
X_test_rnn = scaler.transform(X_test_rnn)
X_test_rnn = X_test_rnn.reshape(shape[0], shape[1], shape[2])
X_test_rnn.shape
(8736, 48, 104)
def my_simple_RNN():
model = Sequential()
model.add(SimpleRNN(units=32, return_sequences=True))
model.add(SimpleRNN(units=32, return_sequences=False))
model.add(Dense(units=1, activation='linear'))
return model
simple_rnn_1, simple_rnn_2 = my_simple_RNN(), my_simple_RNN()
simple_rnn_1.compile(optimizer='SGD', loss='mean_squared_error')
simple_rnn_2.compile(optimizer='SGD', loss='mean_squared_error')
X_train_rnn.shape, y_train.shape
WARNING:tensorflow:From /home/sunflowa/Anaconda/lib/python3.7/site-packages/tensorflow/python/ops/resource_variable_ops.py:435: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
((8712, 48, 104), (8712, 2))
simple_rnn_1.fit(x=X_train_rnn, y=np.array(y_train.iloc[:,0]), epochs=20, batch_size=32)
WARNING:tensorflow:From /home/sunflowa/Anaconda/lib/python3.7/site-packages/tensorflow/python/keras/utils/losses_utils.py:170: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
WARNING:tensorflow:From /home/sunflowa/Anaconda/lib/python3.7/site-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Epoch 1/20
8712/8712 [==============================] - 3s 391us/sample - loss: 4892.4747
Epoch 2/20
8712/8712 [==============================] - 2s 280us/sample - loss: 3132.7046
Epoch 3/20
8712/8712 [==============================] - 2s 281us/sample - loss: 3124.5193
Epoch 4/20
8712/8712 [==============================] - 3s 291us/sample - loss: 3087.9552
Epoch 5/20
8712/8712 [==============================] - 2s 281us/sample - loss: 2996.4712
Epoch 6/20
8712/8712 [==============================] - 3s 306us/sample - loss: 3059.7507
Epoch 7/20
8712/8712 [==============================] - 3s 300us/sample - loss: 3109.1124
Epoch 8/20
8712/8712 [==============================] - 2s 285us/sample - loss: 3041.8741
Epoch 9/20
8712/8712 [==============================] - 2s 284us/sample - loss: 2947.8813
Epoch 10/20
8712/8712 [==============================] - 2s 284us/sample - loss: 2876.6954
Epoch 11/20
8712/8712 [==============================] - 2s 286us/sample - loss: 2844.9381
Epoch 12/20
8712/8712 [==============================] - 2s 284us/sample - loss: 2847.9984
Epoch 13/20
8712/8712 [==============================] - 2s 284us/sample - loss: 2920.4317
Epoch 14/20
8712/8712 [==============================] - 2s 287us/sample - loss: 2921.8935
Epoch 15/20
8712/8712 [==============================] - 2s 287us/sample - loss: 2920.0885
Epoch 16/20
8712/8712 [==============================] - 2s 286us/sample - loss: 2901.7930
Epoch 17/20
8712/8712 [==============================] - 2s 285us/sample - loss: 2922.2052
Epoch 18/20
8712/8712 [==============================] - 2s 285us/sample - loss: 2872.7533
Epoch 19/20
8712/8712 [==============================] - 2s 286us/sample - loss: 2823.4115
Epoch 20/20
8712/8712 [==============================] - 2s 285us/sample - loss: 2872.8206
<tensorflow.python.keras.callbacks.History at 0x7fe376d67828>
simple_rnn_2.fit(x=X_train_rnn, y=np.array(y_train.iloc[:,1]), epochs=20, batch_size=32)
Epoch 1/20
8712/8712 [==============================] - 3s 308us/sample - loss: 4618.0560
Epoch 2/20
8712/8712 [==============================] - 2s 280us/sample - loss: 3643.0039
Epoch 3/20
8712/8712 [==============================] - 2s 280us/sample - loss: 4173.2772
Epoch 4/20
8712/8712 [==============================] - 2s 280us/sample - loss: 5285.1180
Epoch 5/20
8712/8712 [==============================] - 2s 279us/sample - loss: 4142.8450
Epoch 6/20
8712/8712 [==============================] - 3s 303us/sample - loss: 3779.4054
Epoch 7/20
8712/8712 [==============================] - 3s 290us/sample - loss: 3443.7070
Epoch 8/20
8712/8712 [==============================] - 3s 299us/sample - loss: 3273.2908
Epoch 9/20
8712/8712 [==============================] - 3s 287us/sample - loss: 4005.3873
Epoch 10/20
8712/8712 [==============================] - 3s 302us/sample - loss: 3682.9635
Epoch 11/20
8712/8712 [==============================] - 3s 299us/sample - loss: 3561.5160
Epoch 12/20
8712/8712 [==============================] - 3s 292us/sample - loss: 3362.9157
Epoch 13/20
8712/8712 [==============================] - 3s 288us/sample - loss: 4069.3645
Epoch 14/20
8712/8712 [==============================] - 2s 284us/sample - loss: 3971.3454
Epoch 15/20
8712/8712 [==============================] - 2s 287us/sample - loss: 3869.3355
Epoch 16/20
8712/8712 [==============================] - 2s 284us/sample - loss: 3743.0655
Epoch 17/20
8712/8712 [==============================] - 2s 285us/sample - loss: 3666.5237
Epoch 18/20
8712/8712 [==============================] - 2s 285us/sample - loss: 3797.3478
Epoch 19/20
8712/8712 [==============================] - 2s 284us/sample - loss: 3826.5725
Epoch 20/20
8712/8712 [==============================] - 2s 285us/sample - loss: 3646.0687
<tensorflow.python.keras.callbacks.History at 0x7fe35c443f60>
y_train_pred_1 = simple_rnn_1.predict(X_train_rnn)
y_train_pred_2 = simple_rnn_2.predict(X_train_rnn)
y_test_pred_1 = simple_rnn_1.predict(X_test_rnn)
y_test_pred_2 = simple_rnn_2.predict(X_test_rnn)
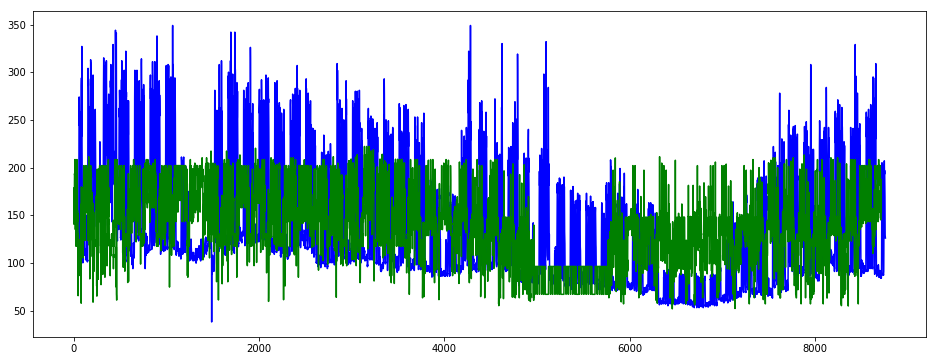
plt.figure(figsize=(16, 6))
plt.plot(y_train.iloc[:, 0], color='blue')
plt.plot(y_train_pred_1, color='green')
plt.show()
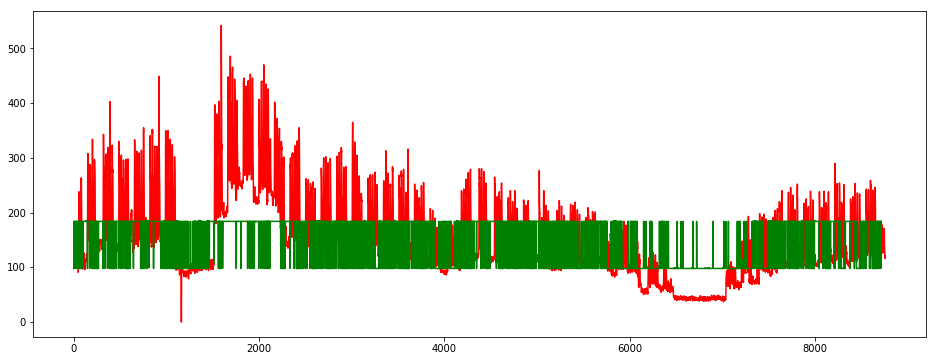
plt.figure(figsize=(16, 6))
plt.plot(y_train.iloc[:, 1], color='red')
plt.plot(y_train_pred_2, color='green')
plt.show()
plt.figure(figsize=(16, 6))
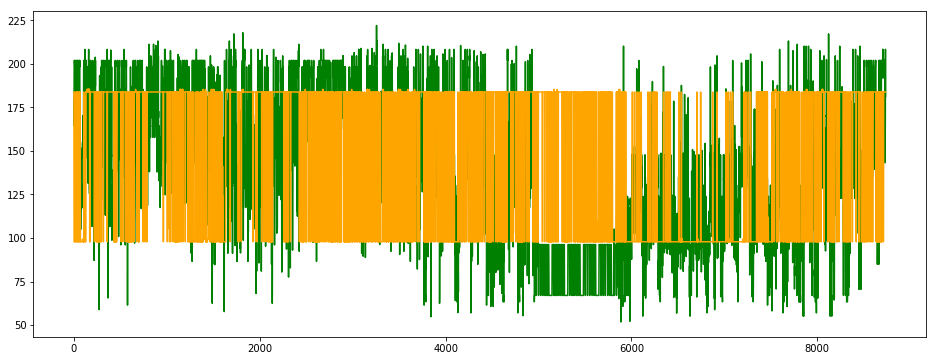
plt.plot(y_test_pred_1, color='green')
plt.plot(y_test_pred_2, color='orange')
plt.show()
GRU
Gated recurrent units (GRUs) are a gating mechanism in recurrent neural networks, introduced in 2014 by Kyunghyun Cho et al. The GRU is like a long short-term memory (LSTM) with forget gate but has fewer parameters than LSTM, as it lacks an output gate. GRU’s performance on certain tasks of polyphonic music modeling and speech signal modeling was found to be similar to that of LSTM. GRUs have been shown to exhibit even better performance on certain smaller datasets.
However, as shown by Gail Weiss & Yoav Goldberg & Eran Yahav, the LSTM is “strictly stronger” than the GRU as it can easily perform unbounded counting, while the GRU cannot. That’s why the GRU fails to learn simple languages that are learnable by the LSTM.
Similarly, as shown by Denny Britz & Anna Goldie & Minh-Thang Luong & Quoc Le of Google Brain, LSTM cells consistently outperform GRU cells in “the first large-scale analysis of architecture variations for Neural Machine Translation.
https://en.wikipedia.org/wiki/Gated_recurrent_unit
def my_GRU():
model = Sequential()
model.add(GRU(units=32, return_sequences=True))
model.add(GRU(units=32, return_sequences=False))
model.add(Dense(units=1, activation='linear'))
return model
gru_1, gru_2 = my_GRU(), my_GRU()
gru_1.compile(optimizer='SGD', loss='mean_squared_error')
gru_2.compile(optimizer='SGD', loss='mean_squared_error')
gru_1.fit(x=X_train_rnn, y=np.array(y_train.iloc[:,0]), epochs=20, batch_size=32)
Epoch 1/20
8712/8712 [==============================] - 8s 946us/sample - loss: 4140.4470
Epoch 2/20
8712/8712 [==============================] - 7s 829us/sample - loss: 2775.6613
Epoch 3/20
8712/8712 [==============================] - 7s 834us/sample - loss: 2582.9657
Epoch 4/20
8712/8712 [==============================] - 7s 834us/sample - loss: 2586.7794
Epoch 5/20
8712/8712 [==============================] - 7s 836us/sample - loss: 2607.1739
Epoch 6/20
8712/8712 [==============================] - 7s 835us/sample - loss: 2584.2904
Epoch 7/20
8712/8712 [==============================] - 7s 838us/sample - loss: 2497.3655
Epoch 8/20
8712/8712 [==============================] - 7s 838us/sample - loss: 2488.9214
Epoch 9/20
8712/8712 [==============================] - 7s 842us/sample - loss: 2455.1357
Epoch 10/20
8712/8712 [==============================] - 7s 840us/sample - loss: 2407.8460
Epoch 11/20
8712/8712 [==============================] - 7s 841us/sample - loss: 2365.4689
Epoch 12/20
8712/8712 [==============================] - 7s 845us/sample - loss: 2310.7510
Epoch 13/20
8712/8712 [==============================] - 7s 846us/sample - loss: 2316.9849
Epoch 14/20
8712/8712 [==============================] - 7s 844us/sample - loss: 2298.8346
Epoch 15/20
8712/8712 [==============================] - 7s 843us/sample - loss: 2296.2690
Epoch 16/20
8712/8712 [==============================] - 7s 842us/sample - loss: 2269.9935
Epoch 17/20
8712/8712 [==============================] - 7s 842us/sample - loss: 2289.1222
Epoch 18/20
8712/8712 [==============================] - 7s 841us/sample - loss: 2261.0284
Epoch 19/20
8712/8712 [==============================] - 7s 843us/sample - loss: 2282.3054
Epoch 20/20
8712/8712 [==============================] - 7s 845us/sample - loss: 2274.4464
<tensorflow.python.keras.callbacks.History at 0x7fe2fee01d68>
gru_2.fit(x=X_train_rnn, y=np.array(y_train.iloc[:,1]), epochs=20, batch_size=32)
Epoch 1/20
8712/8712 [==============================] - 8s 915us/sample - loss: 4867.0947
Epoch 2/20
8712/8712 [==============================] - 7s 832us/sample - loss: 3309.2133
Epoch 3/20
8712/8712 [==============================] - 7s 833us/sample - loss: 3212.8495
Epoch 4/20
8712/8712 [==============================] - 7s 833us/sample - loss: 3180.4730
Epoch 5/20
8712/8712 [==============================] - 7s 853us/sample - loss: 3156.5066
Epoch 6/20
8712/8712 [==============================] - 8s 891us/sample - loss: 3167.0353
Epoch 7/20
8712/8712 [==============================] - 8s 874us/sample - loss: 3118.7520
Epoch 8/20
8712/8712 [==============================] - 7s 852us/sample - loss: 3020.1702
Epoch 9/20
8712/8712 [==============================] - 8s 863us/sample - loss: 3062.5642
Epoch 10/20
8712/8712 [==============================] - 7s 857us/sample - loss: 3062.4002
Epoch 11/20
8712/8712 [==============================] - 7s 845us/sample - loss: 3042.2752
Epoch 12/20
8712/8712 [==============================] - 7s 851us/sample - loss: 2970.8858
Epoch 13/20
8712/8712 [==============================] - 7s 856us/sample - loss: 3070.2262
Epoch 14/20
8712/8712 [==============================] - 7s 855us/sample - loss: 3030.4804
Epoch 15/20
8712/8712 [==============================] - 7s 852us/sample - loss: 3084.9177
Epoch 16/20
8712/8712 [==============================] - 8s 862us/sample - loss: 3090.2180
Epoch 17/20
8712/8712 [==============================] - 7s 853us/sample - loss: 3071.2044
Epoch 18/20
8712/8712 [==============================] - 7s 852us/sample - loss: 3070.6416
Epoch 19/20
8712/8712 [==============================] - 7s 847us/sample - loss: 3054.4008
Epoch 20/20
8712/8712 [==============================] - 7s 855us/sample - loss: 3024.6538
<tensorflow.python.keras.callbacks.History at 0x7fe2fd90ceb8>
y_train_pred_1 = gru_1.predict(X_train_rnn)
y_train_pred_2 = gru_2.predict(X_train_rnn)
y_test_pred_1 = gru_1.predict(X_test_rnn)
y_test_pred_2 = gru_2.predict(X_test_rnn)
plt.figure(figsize=(16, 6))
plt.plot(y_train.iloc[:, 0], color='blue')
plt.plot(y_train_pred_1, color='green')
plt.show()
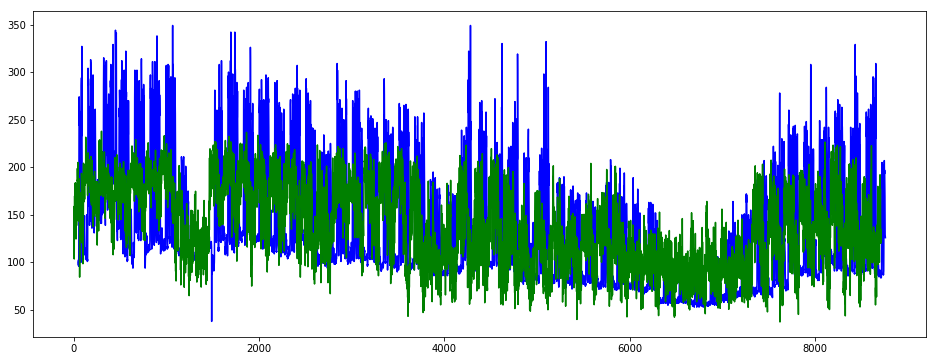
plt.figure(figsize=(16, 6))
plt.plot(y_train.iloc[:, 1], color='red')
plt.plot(y_train_pred_2, color='green')
plt.show()
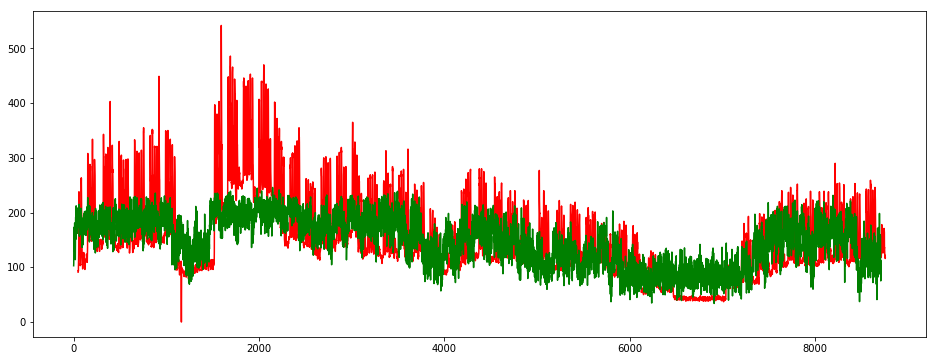
plt.figure(figsize=(16, 6))
plt.plot(y_test_pred_1, color='green')
plt.plot(y_test_pred_2, color='orange')
plt.show()
Results comparison and conclusions
df_score = pd.DataFrame({'Model / Site':['Linear Reg / Site1', 'Linear Reg / Site2',
'Lasso Reg / Site1', 'Lasso Reg / Site2',
'ElasticNet Reg / Site1', 'ElasticNet Reg / Site2',
'SVM base linear / Site1', 'SVM base linear / Site2',
'SVM base rbf / Site1', 'SVM base rbf / Site2'],
'weighted MSA':[res_lin_reg_1, res_lin_reg_2,
res_lasso_1, res_lasso_2,
res_elasticnet_1, res_elasticnet_2,
res_svr_1, res_svr_2,
res_svr_base_rbf_1, res_svr_base_rbf_2]})
ax = df_score.plot.barh(y='weighted MSA', x='Model / Site')
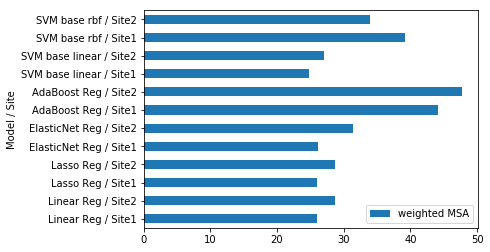
- Except the SVM model with an rbf base, all models doesn’t perform better for the 2nd site, which can be explained by the fact that site doesn’t present regular oscillations.
- Finally, Linear Reg, Lasso and ElasticNet have similar results, because regularization doesn’t help to predict well spikes
- SVM base rbf and Adaboost have worst results than linear regression w/ or w/o regularization.
All these models don’t work well when it comes to time series, in the next part we’ll use the SARIMA library and Recurrent Neural Networks R.N.N which are more appropriate for this kind of prediction.
Ideas
- fill NA with continuous values, mean or median of the week depending where NAs are
- open data for missing temperatures
- add sunlight hours
- try w & w/o get dummies for hours, weekdays
- scaler : fit transform on X/y train & transform on X test
- more function for automation
- RNN
- SARIMA or ARIMA
https://machinelearningmastery.com/decompose-time-series-data-trend-seasonality/
https://www.kaggle.com/niyamatalmass/machine-learning-for-time-series-analysis
https://mapr.com/blog/deep-learning-tensorflow/
https://towardsdatascience.com/how-not-to-use-machine-learning-for-time-series-forecasting-avoiding-the-pitfalls-19f9d7adf424
https://machinelearningmastery.com/how-to-grid-search-deep-learning-models-for-time-series-forecasting/
Really interesting posts :
https://machinelearningmastery.com/multi-step-time-series-forecasting-with-machine-learning-models-for-household-electricity-consumption/
https://medium.com/@alexrachnog/deep-learning-the-final-frontier-for-signal-processing-and-time-series-analysis-734307167ad6
https://towardsdatascience.com/time-series-machine-learning-regression-framework-9ea33929009a
